網頁爬蟲 - python 爬蟲怎么處理json內容
問題描述
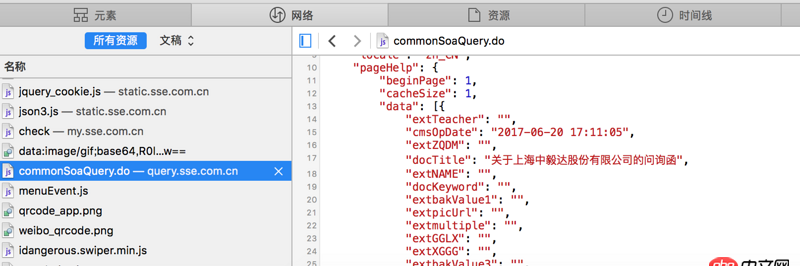
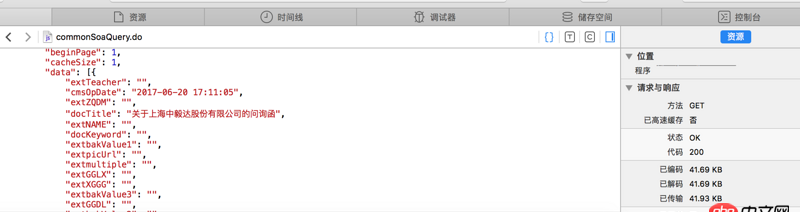
看不清的話 網站地址是http://www.sse.com.cn/disclos...紅字是我需要的內容 但是我提取不出來求教怎么操作
問題解答
回答1:import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5’headers = { ’Referer’:’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’:’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36’}r = requests.get(url, headers=headers)print r.json()[’result’]回答2:
import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5&_=1498029409382’session = requests.session()session.headers.update({ ’Referer’: ’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’: ’Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36’})result = session.get(url).json()print result
相關文章:
1. mysql - 如何減少使用或者不用LEFT JOIN查詢?2. 視頻文件不能播放,怎么辦?3. mysql - jdbc的問題4. Python爬蟲如何爬取span和span中間的內容并分別存入字典里?5. 網頁爬蟲 - python 爬取網站 并解析非json內容6. Python如何播放還存在StringIO中的MP3?7. python - 我在使用pip install -r requirements.txt下載時,為什么部分能下載,部分不能下載8. mysql - 分庫分表、分區、讀寫分離 這些都是用在什么場景下 ,會帶來哪些效率或者其他方面的好處9. node.js - nodejs開發中常用的連接mysql的庫10. python - 編碼問題求助
 網公網安備
網公網安備