文章詳情頁
python - scrapy運(yùn)行爬蟲一打開就關(guān)閉了沒有爬取到數(shù)據(jù)是什么原因
瀏覽:63日期:2022-08-05 15:09:38
問題描述
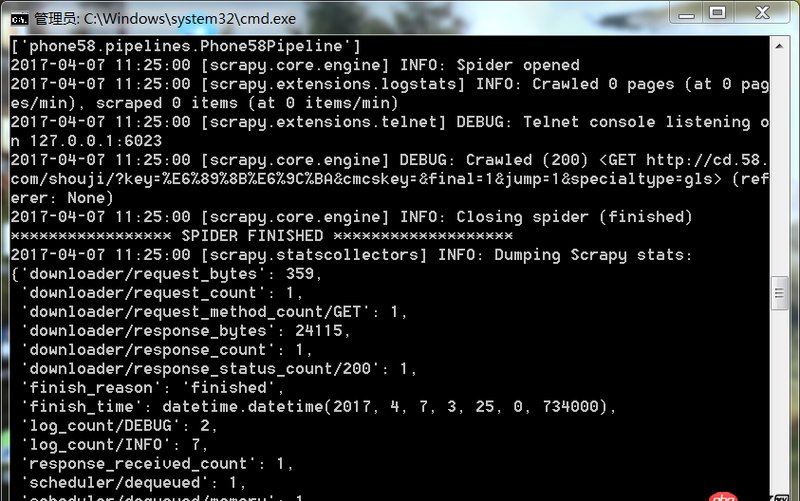
爬蟲運(yùn)行遇到如此問題要怎么解決
問題解答
回答1:很可能是你的爬取規(guī)則出錯(cuò),也就是說你的spider代碼里面的xpath(或者其他解析工具)的規(guī)則錯(cuò)誤。導(dǎo)致沒爬取到。你可以把網(wǎng)址print出來,看看是不是[]
相關(guān)文章:
1. python - Django 表單問題?2. mysql - sql 語句更改表結(jié)構(gòu),添加多個(gè)列,怎么寫?3. 如何修改phpstudy的phpmyadmin放到其他地方4. javascript - 網(wǎng)頁中嵌套iframe,網(wǎng)頁和iframe viewport不同,怎么能讓iframe中的網(wǎng)頁不變形5. 關(guān)于Mysql聯(lián)合查詢6. css3 - 這個(gè)右下角折角用css怎么畫出來?7. javascript - 百度搜索網(wǎng)站,如何讓搜索結(jié)果顯示一張圖片加上一段描述,如圖;求教8. javascript - main head .intro-text{width:40%} main head{display:flex}為何無效?9. pip安裝提示Twisted錯(cuò)誤問題(Python3.6.4安裝Twisted錯(cuò)誤)10. 索引 - 請(qǐng)教下Mysql大數(shù)據(jù)量的聯(lián)合查詢
排行榜
熱門標(biāo)簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備