python - pandas讀取中文的時(shí)候亂碼 要如何解決?
問(wèn)題描述
下載了一份新浪微博的數(shù)據(jù),但是原始數(shù)據(jù)是用csv的,在mac上沒(méi)辦法直接打開(kāi),讀取的時(shí)候,也會(huì)錯(cuò)誤,會(huì)出現(xiàn)
UnicodeDecodeError: ’utf-8’ codec can’t decode byte 0x84 in position 36: invalid start byte
然后自己google,發(fā)現(xiàn)read_csv(’file’, encoding = 'ISO-8859-1') 這樣的時(shí)候讀取不會(huì)有錯(cuò)
但是讀取進(jìn)來(lái)發(fā)現(xiàn)是這樣的:
中文全部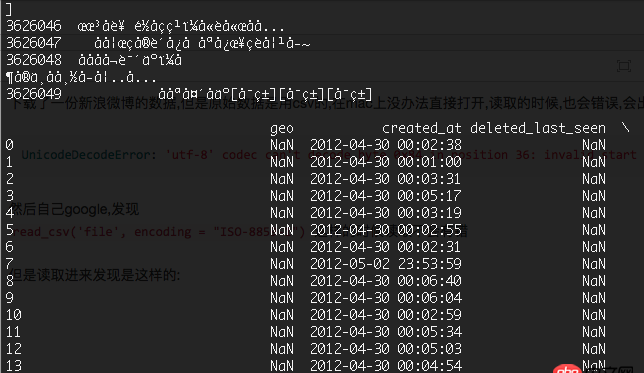
然后測(cè)試了read_csv(’file’, encoding = 'gbk')read_csv(’file’, encoding = 'utf8')read_csv(’file’, encoding = 'gb18030')總之就是各種不行~基本的情況如下:
UnicodeDecodeError: ’gb18030’ codec can’t decode byte 0xaf in position 12: incomplete multibyte sequence
有大神遇到類似的情況嗎?
有大神說(shuō)要數(shù)據(jù) 因?yàn)楸容^大,熱心的人可以看看 不過(guò)我覺(jué)得挺有用的下面是微博的數(shù)據(jù)鏈接:http://pan.baidu.com/s/1jHCOwCI 密碼:x58f
補(bǔ)充一下代碼吧~上面隨意一個(gè)文件下載下來(lái)(是csv格式的)然后用pandas打開(kāi)就會(huì)出錯(cuò)~
import pandasdf = pandas.read_csv('week1.csv')
問(wèn)題解答
回答1:給代碼和原數(shù)據(jù)
你寫(xiě)點(diǎn)能代碼+有代表性的數(shù)據(jù) 即可,別搞幾G的大數(shù)據(jù)阿~
誰(shuí)看啊?
回答2:跟你一樣的情況,試了很多編碼仍然沒(méi)有用,但是看數(shù)據(jù)用UTF8編碼的話,有的數(shù)據(jù)能轉(zhuǎn)換成功,所以我暫時(shí)能想到的辦法就是用open去按行讀取,如果出現(xiàn)編碼轉(zhuǎn)換錯(cuò)誤就丟掉,這樣下來(lái)數(shù)據(jù)量其實(shí)也不少
回答3:你也可以試試用cp1252。最好的方法是先通過(guò)chardet包(https://pypi.python.org/pypi/...)看文件具體上用什么encoding。
回答4:試過(guò)了沒(méi)有問(wèn)題呀,我猜想應(yīng)該是你環(huán)境編碼問(wèn)題吧,可以嘗試一下以下代碼
#coding=utf-8import pandas as pdimport sysreload(sys)sys.setdefaultencoding('utf-8')df = pd.read_csv(’week1.csv’, encoding=’utf-8’, nrows=10)print df
相關(guān)文章:
1. 獲取上次登錄ip的原理是啥?2. 為什么點(diǎn)擊登陸沒(méi)反應(yīng)3. mysql報(bào)錯(cuò) unknown column ’a.plat’ in ON clause4. fetch_field_direct()報(bào)錯(cuò)5. phpstudy v8打開(kāi)數(shù)據(jù)庫(kù)就出錯(cuò),而phpstudy 2018不會(huì)6. 在視圖里面寫(xiě)php原生標(biāo)簽不是要迫不得已的情況才寫(xiě)嗎7. 求救一下,用新版的phpstudy,數(shù)據(jù)庫(kù)過(guò)段時(shí)間會(huì)消失是什么情況?8. 為什么說(shuō)非對(duì)象調(diào)用成員函數(shù)fetch()9. 沒(méi)有輸出結(jié)果,也沒(méi)有報(bào)錯(cuò)信息10. 請(qǐng)問(wèn)下tp6框架的緩存在哪里設(shè)置,或者說(shuō)關(guān)閉?
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備