文章詳情頁
網頁爬蟲 - Python爬蟲返回狀態碼與實際情況不符?
瀏覽:200日期:2022-09-03 18:57:11
問題描述
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如這個爬蟲,輸出狀態碼是200。
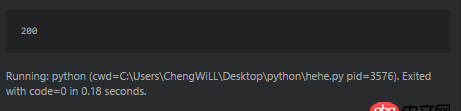
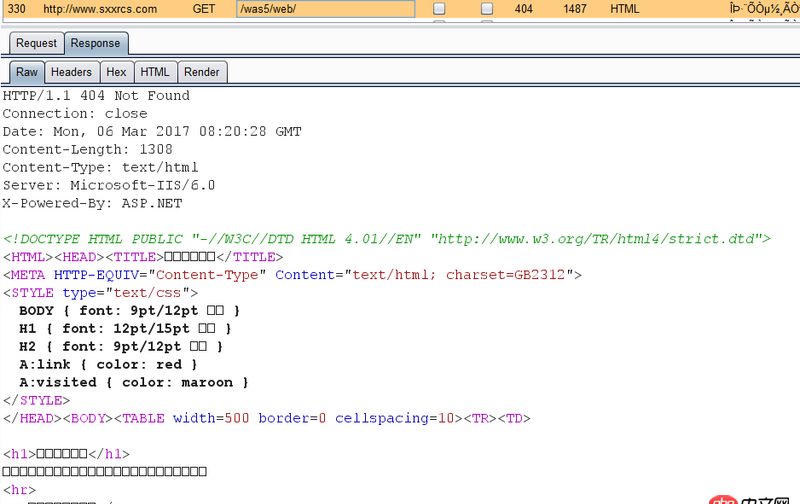
可是直接訪問http://www.sxxrcs.com/was5/web/是404,抓包響應的也是404,請問這是為什么?
問題解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相關文章:
1. docker - 如何修改運行中容器的配置2. dockerfile - [docker build image失敗- npm install]3. 在windows下安裝docker Toolbox 啟動Docker Quickstart Terminal 失敗!4. docker綁定了nginx端口 外部訪問不到5. angular.js - angular內容過長展開收起效果6. 為什么我ping不通我的docker容器呢???7. docker不顯示端口映射呢?8. nignx - docker內nginx 80端口被占用9. docker - 各位電腦上有多少個容器啊?容器一多,自己都搞混了,咋辦呢?10. debian - docker依賴的aufs-tools源碼哪里可以找到啊?
排行榜
 網公網安備
網公網安備