一文讀懂python Scrapy爬蟲框架
先看官網(wǎng)上的說明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
Scrapy是一個(gè)為了爬取網(wǎng)站數(shù)據(jù),提取結(jié)構(gòu)性數(shù)據(jù)而編寫的應(yīng)用框架。可以應(yīng)用在包括數(shù)據(jù)挖掘,信息處理或存儲(chǔ)歷史數(shù)據(jù)等一系列的程序中。
其最初是為了頁面抓取 (更確切來說, 網(wǎng)絡(luò)抓取 )所設(shè)計(jì)的, 也可以應(yīng)用在獲取API所返回的數(shù)據(jù)(例如 Amazon Associates Web Services ) 或者通用的網(wǎng)絡(luò)爬蟲。
Scrapy是一個(gè)非常好用的爬蟲框架,它不僅提供了一些開箱即用的基礎(chǔ)組件,還提供了強(qiáng)大的自定義功能。
# Scrapy 安裝
Scrapy 官網(wǎng):https://scrapy.org/
各位同學(xué)的電腦環(huán)境應(yīng)該和小編的相差不遠(yuǎn)(如果是使用 win10 的話) 安裝過程需要10分鐘左右
安裝命令:
pip install scrapy
由于 Scrapy 依賴了大量的第三方的包,所以在執(zhí)行上面的命令后并不會(huì)馬上就下載 Scrapy ,而是會(huì)先不斷的下載第三方包,包括并不限于以下幾種:
pyOpenSSL:Python 用于支持 SSL(Security Socket Layer)的包。 cryptography:Python 用于加密的庫。 CFFI:Python 用于調(diào)用 C 的接口庫。 zope.interface:為 Python 缺少接口而提供擴(kuò)展的庫。 lxml:一個(gè)處理 XML、HTML 文檔的庫,比 Python 內(nèi)置的 xml 模塊更好用。 cssselect:Python 用于處理 CSS 選擇器的擴(kuò)展包。 Twisted:為 Python 提供的基于事件驅(qū)動(dòng)的網(wǎng)絡(luò)引擎包。 ……如果安裝不成功多試兩次 或者 執(zhí)行pip install --upgrade pip 后再執(zhí)行 pip install scrapy
等待命令執(zhí)行完成后,直接輸入 scrapy 進(jìn)行驗(yàn)證。
C:UsersAdministrator>scrapyScrapy 2.4.0 - no active projectAvailable commands:bench Run quick benchmark test...
版本號可能會(huì)有差別,不用太在意
如果能正常出現(xiàn)以上內(nèi)容,說明我們已經(jīng)安裝成功了。
理論上 Scrapy 安裝出現(xiàn)各種問題才算正常情況
三、Scrapy創(chuàng)建項(xiàng)目Scrapy 提供了一個(gè)命令來創(chuàng)建項(xiàng)目 scrapy 命令,在命令行上運(yùn)行:
scrapy startproject jianshu
我們創(chuàng)建一個(gè)項(xiàng)目jianshu用來爬取簡書首頁熱門文章的所有信息。
jianshu/ scrapy.cfg jianshu/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...
spiders文件夾下就是你要實(shí)現(xiàn)爬蟲功能(具體如何爬取數(shù)據(jù)的代碼),爬蟲的核心。在spiders文件夾下自己創(chuàng)建一個(gè)spider,用于爬取簡書首頁熱門文章。
scrapy.cfg是項(xiàng)目的配置文件。
settings.py用于設(shè)置請求的參數(shù),使用代理,爬取數(shù)據(jù)后文件保存等。
items.py 自己預(yù)計(jì)需要爬取的內(nèi)容
middlewares.py自定義中間件的文件
pipelines.py 管道,保持?jǐn)?shù)據(jù)
項(xiàng)目的目錄就用網(wǎng)圖來展示一下吧
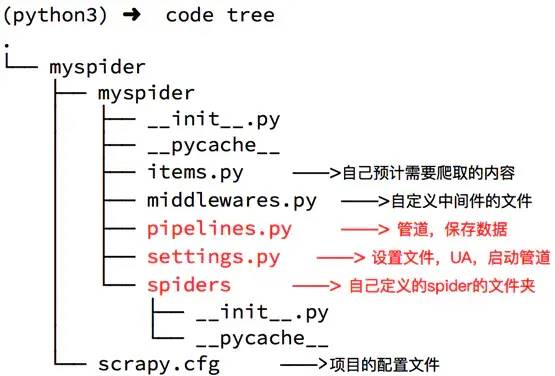
image Scrapy爬取簡書首頁熱門文章
cd到Jianshu項(xiàng)目中,生成一個(gè)爬蟲:
scrapy genspider jianshublog www.jianshu.com
這種方式生成的是常規(guī)爬蟲
1)新建jianshuSpider
import scrapyclass JianshublogSpider(scrapy.Spider): name = ’jianshublog’ allowed_domains = [’www.jianshu.com’] start_urls = [’http://www.jianshu.com/’] def parse(self, response): pass
可以看到,這個(gè)類里面有三個(gè)屬性 name 、 allowed_domains 、 start_urls 和一個(gè)parse()方法。
name,它是每個(gè)項(xiàng)目唯一的名字,用來區(qū)分不同的 Spider。
allowed_domains,它是允許爬取的域名,如果初始或后續(xù)的請求鏈接不是這個(gè)域名下的,則請求鏈接會(huì)被過濾掉。start_urls,它包含了 Spider 在啟動(dòng)時(shí)爬取的 url 列表,初始請求是由它來定義的。
parse,它是 Spider 的一個(gè)方法。默認(rèn)情況下,被調(diào)用時(shí) start_urls 里面的鏈接構(gòu)成的請求完成下載執(zhí)行后,返回的響應(yīng)就會(huì)作為唯一的參數(shù)傳遞給這個(gè)函數(shù)。該方法負(fù)責(zé)解析返回的響應(yīng)、提取數(shù)據(jù)或者進(jìn)一步生成要處理的請求。
到這里我們就清楚了,parse() 方法中的 response 是前面的 start_urls中鏈接的爬取結(jié)果,所以在 parse() 方法中,我們可以直接對爬取的結(jié)果進(jìn)行解析。
修改USER_AGENT
打開settings.py 添加 UA 頭信息
USER_AGENT = ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36’
修改`parse`方法解析網(wǎng)頁
我們打開簡書首頁 右鍵檢查(ctrl+shift+I)發(fā)現(xiàn)所有的博客頭條都放在類名.note-list .content 的div 節(jié)點(diǎn)里面
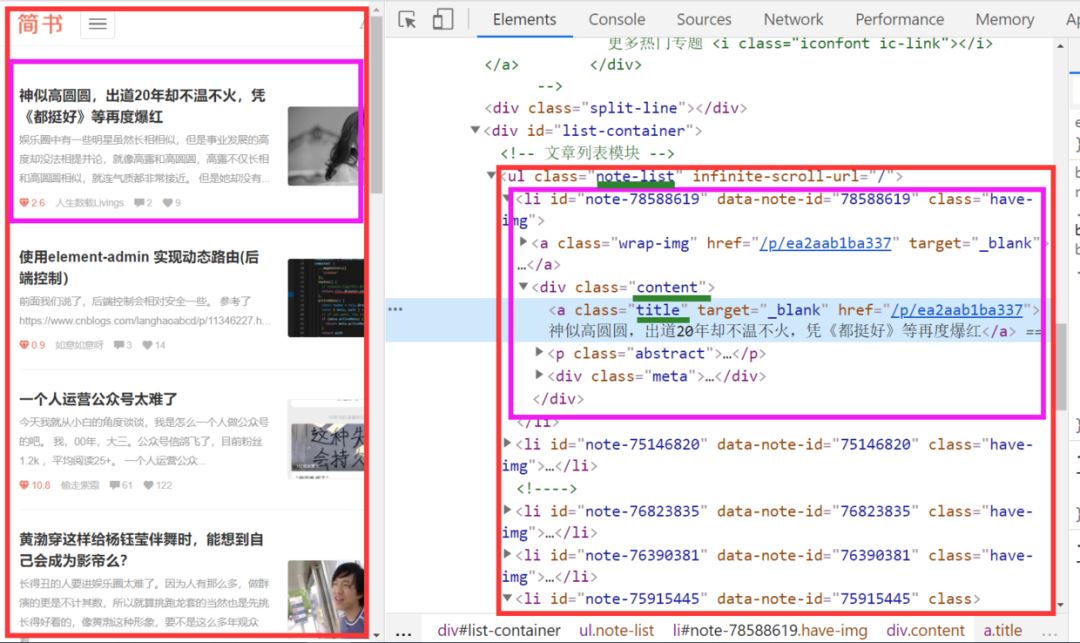
修改jianshublog.py代碼如下
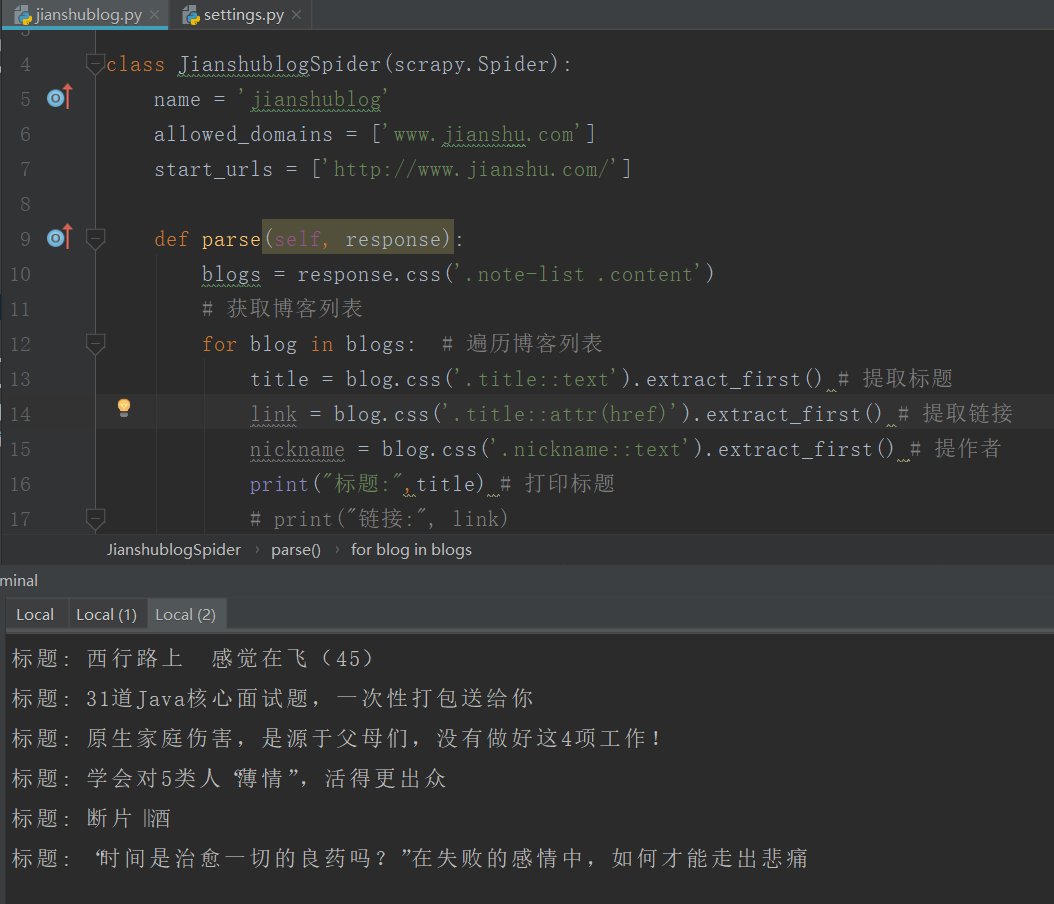
jianshublog.py
import scrapy class JianshublogSpider(scrapy.Spider): name = ’jianshublog’ allowed_domains = [’www.jianshu.com’] start_urls = [’http://www.jianshu.com/’] def parse(self, response): blogs = response.css(’.note-list .content’) # 獲取博客列表 for blog in blogs: # 遍歷博客列表 title = blog.css(’.title::text’).extract_first() # 提取標(biāo)題 link = blog.css(’.title::attr(href)’).extract_first() # 提取鏈接 nickname = blog.css(’.nickname::text’).extract_first() # 提作者 print('標(biāo)題:',title) # 打印標(biāo)題 # print('鏈接:', link) # print('作者:', nickname)
最后別忘了執(zhí)行爬蟲命令
scrapy crawl jianshublog
整個(gè)項(xiàng)目就完成啦
下一講我們把文章數(shù)據(jù)爬取出來,存儲(chǔ)在csv文件里面
到此這篇關(guān)于一文讀懂python Scrapy爬蟲框架的文章就介紹到這了,更多相關(guān)python Scrapy爬蟲框架內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. XHTML 1.0:標(biāo)記新的開端2. html清除浮動(dòng)的6種方法示例3. ASP腳本組件實(shí)現(xiàn)服務(wù)器重啟4. 低版本IE正常運(yùn)行HTML5+CSS3網(wǎng)站的3種解決方案5. xml中的空格之完全解說6. ASP基礎(chǔ)入門第三篇(ASP腳本基礎(chǔ))7. 怎樣才能用js生成xmldom對象,并且在firefox中也實(shí)現(xiàn)xml數(shù)據(jù)島?8. css進(jìn)階學(xué)習(xí) 選擇符9. CSS3中Transition屬性詳解以及示例分享10. 在JSP中使用formatNumber控制要顯示的小數(shù)位數(shù)方法
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備