Python爬蟲代理池搭建的方法步驟
在眾多的網(wǎng)站防爬措施中,有一種是根據(jù)ip的訪問頻率進(jìn)行限制,即在某一時(shí)間段內(nèi),當(dāng)某個(gè)ip的訪問次數(shù)達(dá)到一定的閥值時(shí),該ip就會(huì)被拉黑、在一段時(shí)間內(nèi)禁止訪問。
應(yīng)對(duì)的方法有兩種:
1. 降低爬蟲的爬取頻率,避免IP被限制訪問,缺點(diǎn)顯而易見:會(huì)大大降低爬取的效率。
2. 搭建一個(gè)IP代理池,使用不同的IP輪流進(jìn)行爬取。
二、搭建思路1、從代理網(wǎng)站(如:西刺代理、快代理、云代理、無憂代理)爬取代理IP;
2、驗(yàn)證代理IP的可用性(使用代理IP去請(qǐng)求指定URL,根據(jù)響應(yīng)驗(yàn)證代理IP是否生效);
3、將可用的代理IP保存到數(shù)據(jù)庫;
常用代理網(wǎng)站:西刺代理 、云代理 、IP海 、無憂代理 、飛蟻代理 、快代理
三、代碼實(shí)現(xiàn)工程結(jié)構(gòu)如下:
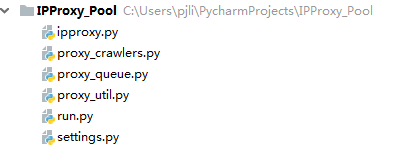
ipproxy.py
IPProxy代理類定義了要爬取的IP代理的字段信息和一些基礎(chǔ)方法。
# -*- coding: utf-8 -*-import reimport timefrom settings import PROXY_URL_FORMATTERschema_pattern = re.compile(r’http|https$’, re.I)ip_pattern = re.compile(r’^([0-9]{1,3}.){3}[0-9]{1,3}$’, re.I)port_pattern = re.compile(r’^[0-9]{2,5}$’, re.I)class IPProxy: ’’’ { 'schema': 'http', # 代理的類型 'ip': '127.0.0.1', # 代理的IP地址 'port': '8050', # 代理的端口號(hào) 'used_total': 11, # 代理的使用次數(shù) 'success_times': 5, # 代理請(qǐng)求成功的次數(shù) 'continuous_failed': 3, # 使用代理發(fā)送請(qǐng)求,連續(xù)失敗的次數(shù) 'created_time': '2018-05-02' # 代理的爬取時(shí)間 } ’’’ def __init__(self, schema, ip, port, used_total=0, success_times=0, continuous_failed=0, created_time=None): '''Initialize the proxy instance''' if schema == '' or schema is None: schema = 'http' self.schema = schema.lower() self.ip = ip self.port = port self.used_total = used_total self.success_times = success_times self.continuous_failed = continuous_failed if created_time is None: created_time = time.strftime(’%Y-%m-%d’, time.localtime(time.time())) self.created_time = created_time def _get_url(self): ’’’ Return the proxy url’’’ return PROXY_URL_FORMATTER % {’schema’: self.schema, ’ip’: self.ip, ’port’: self.port} def _check_format(self): ’’’ Return True if the proxy fields are well-formed,otherwise return False’’’ if self.schema is not None and self.ip is not None and self.port is not None: if schema_pattern.match(self.schema) and ip_pattern.match(self.ip) and port_pattern.match(self.port):return True return False def _is_https(self): ’’’ Return True if the proxy is https,otherwise return False’’’ return self.schema == ’https’ def _update(self, successed=False): ’’’ Update proxy based on the result of the request’s response’’’ self.used_total = self.used_total + 1 if successed: self.continuous_failed = 0 self.success_times = self.success_times + 1 else: print(self.continuous_failed) self.continuous_failed = self.continuous_failed + 1if __name__ == ’__main__’: proxy = IPProxy(’HTTPS’, ’192.168.2.25’, '8080') print(proxy._get_url()) print(proxy._check_format()) print(proxy._is_https())
settings.py
settings.py中匯聚了工程所需要的配置信息。
# 指定Redis的主機(jī)名和端口REDIS_HOST = ’localhost’REDIS_PORT = 6379# 代理保存到Redis key 格式化字符串PROXIES_REDIS_FORMATTER = ’proxies::{}’# 已經(jīng)存在的HTTP代理和HTTPS代理集合PROXIES_REDIS_EXISTED = ’proxies::existed’# 最多連續(xù)失敗幾次MAX_CONTINUOUS_TIMES = 3# 代理地址的格式化字符串PROXY_URL_FORMATTER = ’%(schema)s://%(ip)s:%(port)s’USER_AGENT_LIST = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1', 'Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6', 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6', 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5', 'Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3', 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3', 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3', 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24', 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24']# 爬取到的代理保存前先檢驗(yàn)是否可用,默認(rèn)TruePROXY_CHECK_BEFOREADD = True# 檢驗(yàn)代理可用性的請(qǐng)求地址,支持多個(gè)PROXY_CHECK_URLS = {’https’:[’https://icanhazip.com’],’http’:[’http://icanhazip.com’]}
proxy_util.py
proxy_util.py 中主要定義了一些實(shí)用方法,例如:proxy_to_dict(proxy)用來將IPProxy代理實(shí)例轉(zhuǎn)換成字典;proxy_from_dict(d)用來將字典轉(zhuǎn)換為IPProxy實(shí)例;request_page()用來發(fā)送請(qǐng)求;_is_proxy_available()用來校驗(yàn)代理IP是否可用。
# -*- coding: utf-8 -*-import randomimport loggingimport requestsfrom ipproxy import IPProxyfrom settings import USER_AGENT_LIST, PROXY_CHECK_URLS# Setting logger output formatlogging.basicConfig(level=logging.INFO, format=’[%(asctime)-15s] [%(levelname)8s] [%(name)10s ] - %(message)s (%(filename)s:%(lineno)s)’, datefmt=’%Y-%m-%d %T’ )logger = logging.getLogger(__name__)def proxy_to_dict(proxy): d = { 'schema': proxy.schema, 'ip': proxy.ip, 'port': proxy.port, 'used_total': proxy.used_total, 'success_times': proxy.success_times, 'continuous_failed': proxy.continuous_failed, 'created_time': proxy.created_time } return ddef proxy_from_dict(d): return IPProxy(schema=d[’schema’], ip=d[’ip’], port=d[’port’], used_total=d[’used_total’], success_times=d[’success_times’], continuous_failed=d[’continuous_failed’], created_time=d[’created_time’])# Truncate header and tailer blanksdef strip(data): if data is not None: return data.strip() return database_headers = { ’Accept-Encoding’: ’gzip, deflate, br’, ’Accept-Language’: ’en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7’}def request_page(url, options={}, encoding=’utf-8’): '''send a request,get response''' headers = dict(base_headers, **options) if ’User-Agent’ not in headers.keys(): headers[’User-Agent’] = random.choice(USER_AGENT_LIST) logger.info(’正在抓取: ’ + url) try: response = requests.get(url, headers=headers) if response.status_code == 200: logger.info(’抓取成功: ’ + url) return response.content.decode(encoding=encoding) except ConnectionError: logger.error(’抓取失敗’ + url) return Nonedef _is_proxy_available(proxy, options={}): '''Check whether the Proxy is available or not''' headers = dict(base_headers, **options) if ’User-Agent’ not in headers.keys(): headers[’User-Agent’] = random.choice(USER_AGENT_LIST) proxies = {proxy.schema: proxy._get_url()} check_urls = PROXY_CHECK_URLS[proxy.schema] for url in check_urls: try: response = requests.get(url=url, proxies=proxies, headers=headers, timeout=5) except BaseException: logger.info('< ' + url + ' > 驗(yàn)證代理 < ' + proxy._get_url() + ' > 結(jié)果: 不可用 ') else: if response.status_code == 200:logger.info('< ' + url + ' > 驗(yàn)證代理 < ' + proxy._get_url() + ' > 結(jié)果: 可用 ')return True else:logger.info('< ' + url + ' > 驗(yàn)證代理 < ' + proxy._get_url() + ' > 結(jié)果: 不可用 ') return Falseif __name__ == ’__main__’: headers = dict(base_headers) if ’User-Agent’ not in headers.keys(): headers[’User-Agent’] = random.choice(USER_AGENT_LIST) proxies = {'https': 'https://163.125.255.154:9797'} response = requests.get('https://www.baidu.com', headers=headers, proxies=proxies, timeout=3) print(response.content)
proxy_queue.py
代理隊(duì)列用來保存并對(duì)外提供 IP代理,不同的代理隊(duì)列內(nèi)代理IP的保存和提取策略可以不同。在這里, BaseQueue 是所有代理隊(duì)列的基類,其中聲明了所有代理隊(duì)列都需要實(shí)現(xiàn)的保存代理IP、提取代理IP、查看代理IP數(shù)量等接口。示例的 FifoQueue 是一個(gè)先進(jìn)先出隊(duì)列,底層使用 Redis 列表實(shí)現(xiàn),為了確保同一個(gè)代理IP只能被放入隊(duì)列一次,這里使用了一個(gè)Redis proxies::existed 集合進(jìn)行入隊(duì)前重復(fù)校驗(yàn)。
# -*- coding: utf-8 -*-from proxy_util import loggerimport jsonimport redisfrom ipproxy import IPProxyfrom proxy_util import proxy_to_dict, proxy_from_dict, _is_proxy_availablefrom settings import PROXIES_REDIS_EXISTED, PROXIES_REDIS_FORMATTER, MAX_CONTINUOUS_TIMES, PROXY_CHECK_BEFOREADD'''Proxy Queue Base Class'''class BaseQueue(object): def __init__(self, server): '''Initialize the proxy queue instance Parameters ---------- server : StrictRedis Redis client instance ''' self.server = server def _serialize_proxy(self, proxy): '''Serialize proxy instance''' return proxy_to_dict(proxy) def _deserialize_proxy(self, serialized_proxy): '''deserialize proxy instance''' return proxy_from_dict(eval(serialized_proxy)) def __len__(self, schema=’http’): '''Return the length of the queue''' raise NotImplementedError def push(self, proxy, need_check): '''Push a proxy''' raise NotImplementedError def pop(self, schema=’http’, timeout=0): '''Pop a proxy''' raise NotImplementedErrorclass FifoQueue(BaseQueue): '''First in first out queue''' def __len__(self, schema=’http’): '''Return the length of the queue''' return self.server.llen(PROXIES_REDIS_FORMATTER.format(schema)) def push(self, proxy, need_check=PROXY_CHECK_BEFOREADD): '''Push a proxy''' if need_check and not _is_proxy_available(proxy): return elif proxy.continuous_failed < MAX_CONTINUOUS_TIMES and not self._is_existed(proxy): key = PROXIES_REDIS_FORMATTER.format(proxy.schema) self.server.rpush(key, json.dumps(self._serialize_proxy(proxy),ensure_ascii=False)) def pop(self, schema=’http’, timeout=0): '''Pop a proxy''' if timeout > 0: p = self.server.blpop(PROXIES_REDIS_FORMATTER.format(schema.lower()), timeout) if isinstance(p, tuple):p = p[1] else: p = self.server.lpop(PROXIES_REDIS_FORMATTER.format(schema.lower())) if p: p = self._deserialize_proxy(p) self.server.srem(PROXIES_REDIS_EXISTED, p._get_url()) return p def _is_existed(self, proxy): added = self.server.sadd(PROXIES_REDIS_EXISTED, proxy._get_url()) return added == 0if __name__ == ’__main__’: r = redis.StrictRedis(host=’localhost’, port=6379) queue = FifoQueue(r) proxy = IPProxy(’http’, ’218.66.253.144’, ’80’) queue.push(proxy) proxy = queue.pop(schema=’http’) print(proxy._get_url())
proxy_crawlers.py
ProxyBaseCrawler 是所有代理爬蟲的基類,其中只定義了一個(gè) _start_crawl() 方法用來從搜集到的代理網(wǎng)站爬取代理IP。
# -*- coding: utf-8 -*-from lxml import etreefrom ipproxy import IPProxyfrom proxy_util import strip, request_page, loggerclass ProxyBaseCrawler(object): def __init__(self, queue=None, website=None, urls=[]): self.queue = queue self.website = website self.urls = urls def _start_crawl(self): raise NotImplementedErrorclass KuaiDailiCrawler(ProxyBaseCrawler): # 快代理 def _start_crawl(self): for url_dict in self.urls: logger.info('開始爬取 [ ' + self.website + ' ] :::> [ ' + url_dict[’type’] + ' ]') has_more = True url = None while has_more:if ’page’ in url_dict.keys() and str.find(url_dict[’url’], ’{}’) != -1: url = url_dict[’url’].format(str(url_dict[’page’])) url_dict[’page’] = url_dict[’page’] + 1else: url = url_dict[’url’] has_more = Falsehtml = etree.HTML(request_page(url))tr_list = html.xpath('//table[@class=’table table-bordered table-striped’]/tbody/tr')for tr in tr_list: ip = tr.xpath('./td[@data-title=’IP’]/text()')[0] if len( tr.xpath('./td[@data-title=’IP’]/text()')) else None port = tr.xpath('./td[@data-title=’PORT’]/text()')[0] if len( tr.xpath('./td[@data-title=’PORT’]/text()')) else None schema = tr.xpath('./td[@data-title=’類型’]/text()')[0] if len( tr.xpath('./td[@data-title=’類型’]/text()')) else None proxy = IPProxy(schema=strip(schema), ip=strip(ip), port=strip(port)) if proxy._check_format(): self.queue.push(proxy)if tr_list is None: has_more = Falseclass FeiyiDailiCrawler(ProxyBaseCrawler): # 飛蟻代理 def _start_crawl(self): for url_dict in self.urls: logger.info('開始爬取 [ ' + self.website + ' ] :::> [ ' + url_dict[’type’] + ' ]') has_more = True url = None while has_more:if ’page’ in url_dict.keys() and str.find(url_dict[’url’], ’{}’) != -1: url = url_dict[’url’].format(str(url_dict[’page’])) url_dict[’page’] = url_dict[’page’] + 1else: url = url_dict[’url’] has_more = Falsehtml = etree.HTML(request_page(url))tr_list = html.xpath('//div[@id=’main-content’]//table/tr[position()>1]')for tr in tr_list: ip = tr.xpath('./td[1]/text()')[0] if len(tr.xpath('./td[1]/text()')) else None port = tr.xpath('./td[2]/text()')[0] if len(tr.xpath('./td[2]/text()')) else None schema = tr.xpath('./td[4]/text()')[0] if len(tr.xpath('./td[4]/text()')) else None proxy = IPProxy(schema=strip(schema), ip=strip(ip), port=strip(port)) if proxy._check_format(): self.queue.push(proxy)if tr_list is None: has_more = Falseclass WuyouDailiCrawler(ProxyBaseCrawler): # 無憂代理 def _start_crawl(self): for url_dict in self.urls: logger.info('開始爬取 [ ' + self.website + ' ] :::> [ ' + url_dict[’type’] + ' ]') has_more = True url = None while has_more:if ’page’ in url_dict.keys() and str.find(url_dict[’url’], ’{}’) != -1: url = url_dict[’url’].format(str(url_dict[’page’])) url_dict[’page’] = url_dict[’page’] + 1else: url = url_dict[’url’] has_more = Falsehtml = etree.HTML(request_page(url))ul_list = html.xpath('//div[@class=’wlist’][2]//ul[@class=’l2’]')for ul in ul_list: ip = ul.xpath('./span[1]/li/text()')[0] if len(ul.xpath('./span[1]/li/text()')) else None port = ul.xpath('./span[2]/li/text()')[0] if len(ul.xpath('./span[2]/li/text()')) else None schema = ul.xpath('./span[4]/li/text()')[0] if len(ul.xpath('./span[4]/li/text()')) else None proxy = IPProxy(schema=strip(schema), ip=strip(ip), port=strip(port)) if proxy._check_format(): self.queue.push(proxy)if ul_list is None: has_more = Falseclass IPhaiDailiCrawler(ProxyBaseCrawler): # IP海代理 def _start_crawl(self): for url_dict in self.urls: logger.info('開始爬取 [ ' + self.website + ' ] :::> [ ' + url_dict[’type’] + ' ]') has_more = True url = None while has_more:if ’page’ in url_dict.keys() and str.find(url_dict[’url’], ’{}’) != -1: url = url_dict[’url’].format(str(url_dict[’page’])) url_dict[’page’] = url_dict[’page’] + 1else: url = url_dict[’url’] has_more = Falsehtml = etree.HTML(request_page(url))tr_list = html.xpath('//table//tr[position()>1]')for tr in tr_list: ip = tr.xpath('./td[1]/text()')[0] if len(tr.xpath('./td[1]/text()')) else None port = tr.xpath('./td[2]/text()')[0] if len(tr.xpath('./td[2]/text()')) else None schema = tr.xpath('./td[4]/text()')[0] if len(tr.xpath('./td[4]/text()')) else None proxy = IPProxy(schema=strip(schema), ip=strip(ip), port=strip(port)) if proxy._check_format(): self.queue.push(proxy)if tr_list is None: has_more = Falseclass YunDailiCrawler(ProxyBaseCrawler): # 云代理 def _start_crawl(self): for url_dict in self.urls: logger.info('開始爬取 [ ' + self.website + ' ] :::> [ ' + url_dict[’type’] + ' ]') has_more = True url = None while has_more:if ’page’ in url_dict.keys() and str.find(url_dict[’url’], ’{}’) != -1: url = url_dict[’url’].format(str(url_dict[’page’])) url_dict[’page’] = url_dict[’page’] + 1else: url = url_dict[’url’] has_more = Falsehtml = etree.HTML(request_page(url, encoding=’gbk’))tr_list = html.xpath('//table/tbody/tr')for tr in tr_list: ip = tr.xpath('./td[1]/text()')[0] if len(tr.xpath('./td[1]/text()')) else None port = tr.xpath('./td[2]/text()')[0] if len(tr.xpath('./td[2]/text()')) else None schema = tr.xpath('./td[4]/text()')[0] if len(tr.xpath('./td[4]/text()')) else None proxy = IPProxy(schema=strip(schema), ip=strip(ip), port=strip(port)) if proxy._check_format(): self.queue.push(proxy)if tr_list is None: has_more = Falseclass XiCiDailiCrawler(ProxyBaseCrawler): # 西刺代理 def _start_crawl(self): for url_dict in self.urls: logger.info('開始爬取 [ ' + self.website + ' ] :::> [ ' + url_dict[’type’] + ' ]') has_more = True url = None while has_more:if ’page’ in url_dict.keys() and str.find(url_dict[’url’], ’{}’) != -1: url = url_dict[’url’].format(str(url_dict[’page’])) url_dict[’page’] = url_dict[’page’] + 1else: url = url_dict[’url’] has_more = Falsehtml = etree.HTML(request_page(url))tr_list = html.xpath('//table[@id=’ip_list’]//tr[@class!=’subtitle’]')for tr in tr_list: ip = tr.xpath('./td[2]/text()')[0] if len(tr.xpath('./td[2]/text()')) else None port = tr.xpath('./td[3]/text()')[0] if len(tr.xpath('./td[3]/text()')) else None schema = tr.xpath('./td[6]/text()')[0] if len(tr.xpath('./td[6]/text()')) else None if schema.lower() == 'http' or schema.lower() == 'https': proxy = IPProxy(schema=strip(schema), ip=strip(ip), port=strip(port)) if proxy._check_format(): self.queue.push(proxy)if tr_list is None: has_more = False
run.py
通過run.py啟動(dòng)各個(gè)代理網(wǎng)站爬蟲。
# -*- coding: utf-8 -*-import redisfrom proxy_queue import FifoQueuefrom settings import REDIS_HOST, REDIS_PORTfrom proxy_crawlers import WuyouDailiCrawler, FeiyiDailiCrawler, KuaiDailiCrawler, IPhaiDailiCrawler, YunDailiCrawler, XiCiDailiCrawlerr = redis.StrictRedis(host=REDIS_HOST, port=REDIS_PORT)fifo_queue = FifoQueue(r)def run_kuai(): kuaidailiCrawler = KuaiDailiCrawler(queue=fifo_queue, website=’快代理[國內(nèi)高匿]’, urls=[{’url’: ’https://www.kuaidaili.com/free/inha/{}/’, ’type’: ’國內(nèi)高匿’,’page’: 1}, {’url’: ’https://www.kuaidaili.com/free/intr/{}/’, ’type’: ’國內(nèi)普通’,’page’: 1}]) kuaidailiCrawler._start_crawl()def run_feiyi(): feiyidailiCrawler = FeiyiDailiCrawler(queue=fifo_queue, website=’飛蟻代理’, urls=[{’url’: ’http://www.feiyiproxy.com/?page_id=1457’, ’type’: ’首頁推薦’}]) feiyidailiCrawler._start_crawl()def run_wuyou(): wuyoudailiCrawler = WuyouDailiCrawler(queue=fifo_queue, website=’無憂代理’, urls=[{’url’: ’http://www.data5u.com/free/index.html’, ’type’: ’首頁推薦’},{’url’: ’http://www.data5u.com/free/gngn/index.shtml’, ’type’: ’國內(nèi)高匿’},{’url’: ’http://www.data5u.com/free/gnpt/index.shtml’, ’type’: ’國內(nèi)普通’}]) wuyoudailiCrawler._start_crawl()def run_iphai(): crawler = IPhaiDailiCrawler(queue=fifo_queue, website=’IP海代理’,urls=[{’url’: ’http://www.iphai.com/free/ng’, ’type’: ’國內(nèi)高匿’}, {’url’: ’http://www.iphai.com/free/np’, ’type’: ’國內(nèi)普通’}, {’url’: ’http://www.iphai.com/free/wg’, ’type’: ’國外高匿’}, {’url’: ’http://www.iphai.com/free/wp’, ’type’: ’國外普通’}]) crawler._start_crawl()def run_yun(): crawler = YunDailiCrawler(queue=fifo_queue, website=’云代理’, urls=[{’url’: ’http://www.ip3366.net/free/?stype=1&page={}’, ’type’: ’國內(nèi)高匿’, ’page’: 1}, {’url’: ’http://www.ip3366.net/free/?stype=2&page={}’, ’type’: ’國內(nèi)普通’, ’page’: 1}, {’url’: ’http://www.ip3366.net/free/?stype=3&page={}’, ’type’: ’國外高匿’, ’page’: 1}, {’url’: ’http://www.ip3366.net/free/?stype=4&page={}’, ’type’: ’國外普通’, ’page’: 1}]) crawler._start_crawl()def run_xici(): crawler = XiCiDailiCrawler(queue=fifo_queue, website=’西刺代理’,urls=[{’url’: ’https://www.xicidaili.com/’, ’type’: ’首頁推薦’}, {’url’: ’https://www.xicidaili.com/nn/{}’, ’type’: ’國內(nèi)高匿’, ’page’: 1}, {’url’: ’https://www.xicidaili.com/nt/{}’, ’type’: ’國內(nèi)普通’, ’page’: 1}, {’url’: ’https://www.xicidaili.com/wn/{}’, ’type’: ’國外高匿’, ’page’: 1}, {’url’: ’https://www.xicidaili.com/wt/{}’, ’type’: ’國外普通’, ’page’: 1}]) crawler._start_crawl()if __name__ == ’__main__’: run_xici() run_iphai() run_kuai() run_feiyi() run_yun() run_wuyou()
爬取西刺代理時(shí),后臺(tái)日志示例如下:

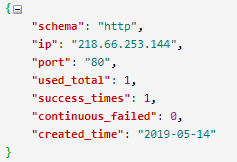
Redis數(shù)據(jù)庫中爬取到的代理IP的數(shù)據(jù)結(jié)構(gòu)如下:

接下來,使用爬取好的代理來請(qǐng)求 http://icanhazip.com 進(jìn)行測(cè)試,代碼如下:
# -*- coding: utf-8 -*-import randomimport requestsfrom proxy_util import loggerfrom run import fifo_queuefrom settings import USER_AGENT_LISTfrom proxy_util import base_headers# 測(cè)試地址url = ’http://icanhazip.com’# 獲取代理proxy = fifo_queue.pop(schema=’http’)proxies = {proxy.schema:proxy._get_url()}# 構(gòu)造請(qǐng)求頭headers = dict(base_headers)if ’User-Agent’ not in headers.keys(): headers[’User-Agent’] = random.choice(USER_AGENT_LIST)response = Nonesuccessed = Falsetry: response = requests.get(url,headers=headers,proxies = proxies,timeout=5)except BaseException: logger.error('使用代理< '+proxy._get_url()+' > 請(qǐng)求 < '+url+' > 結(jié)果: 失敗 ')else: if (response.status_code == 200): logger.info(response.content.decode()) successed = True logger.info('使用代理< ' + proxy._get_url() + ' > 請(qǐng)求 < ' + url + ' > 結(jié)果: 成功 ') else: logger.info(response.content.decode()) logger.info('使用代理< ' + proxy._get_url() + ' > 請(qǐng)求 < ' + url + ' > 結(jié)果: 失敗 ')# 根據(jù)請(qǐng)求的響應(yīng)結(jié)果更新代理proxy._update(successed)# 將代理返還給隊(duì)列,返還時(shí)不校驗(yàn)可用性fifo_queue.push(proxy,need_check=False)
使用 http://218.66.253.144:80 代理請(qǐng)求成功后將代理重新放回隊(duì)列,并將 Redis 中該代理的 used_total 、success_times 、continuous_failed三個(gè)字段信息進(jìn)行了相應(yīng)的更新。
項(xiàng)目地址:https://github.com/pengjunlee/ipproxy_pool.git
到此這篇關(guān)于Python爬蟲代理池搭建的方法步驟的文章就介紹到這了,更多相關(guān)Python爬蟲代理池搭建內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. jsp實(shí)現(xiàn)登錄驗(yàn)證的過濾器2. ASP中實(shí)現(xiàn)字符部位類似.NET里String對(duì)象的PadLeft和PadRight函數(shù)3. jsp+servlet簡(jiǎn)單實(shí)現(xiàn)上傳文件功能(保存目錄改進(jìn))4. 微信開發(fā) 網(wǎng)頁授權(quán)獲取用戶基本信息5. JavaWeb Servlet中url-pattern的使用6. asp批量添加修改刪除操作示例代碼7. 詳解瀏覽器的緩存機(jī)制8. HTML5 Canvas繪制圖形從入門到精通9. css代碼優(yōu)化的12個(gè)技巧10. msxml3.dll 錯(cuò)誤 800c0019 系統(tǒng)錯(cuò)誤:-2146697191解決方法

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備