Python爬蟲使用bs4方法實現(xiàn)數(shù)據(jù)解析
聚焦爬蟲:
爬取頁面中指定的頁面內(nèi)容。
編碼流程:
1.指定url 2.發(fā)起請求 3.獲取響應(yīng)數(shù)據(jù) 4.數(shù)據(jù)解析 5.持久化存儲數(shù)據(jù)解析分類:
1.bs4 2.正則 3.xpath (***)數(shù)據(jù)解析原理概述:
解析的局部的文本內(nèi)容都會在標(biāo)簽之間或者標(biāo)簽對應(yīng)的屬性中進行存儲
1.進行指定標(biāo)簽的定位
2.標(biāo)簽或者標(biāo)簽對應(yīng)的屬性中存儲的數(shù)據(jù)值進行提取(解析)
bs4進行數(shù)據(jù)解析數(shù)據(jù)解析的原理:
1.標(biāo)簽定位
2.提取標(biāo)簽、標(biāo)簽屬性中存儲的數(shù)據(jù)值
bs4數(shù)據(jù)解析的原理:
1.實例化一個BeautifulSoup對象,并且將頁面源碼數(shù)據(jù)加載到該對象中
2.通過調(diào)用BeautifulSoup對象中相關(guān)的屬性或者方法進行標(biāo)簽定位和數(shù)據(jù)提取
環(huán)境安裝:
pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
實例化BeautifulSoup對象步驟:
from bs4 import BeautifulSoup
對象的實例化:
1.將本地的html文檔中的數(shù)據(jù)加載到該對象中
fp = open(’./test.html’,’r’,encoding=’utf-8’)soup = BeautifulSoup(fp,’lxml’)
2.將互聯(lián)網(wǎng)上獲取的頁面源碼加載到該對象中(常用方法,推薦)
page_text = response.textsoup = BeatifulSoup(page_text,’lxml’)
提供的用于數(shù)據(jù)解析的方法和屬性:
soup.tagName:返回的是文檔中第一次出現(xiàn)的tagName對應(yīng)的標(biāo)簽soup.find():find(’tagName’):等同于soup.div
1.屬性定位:
soup.find(’div’,class_/id/attr=’song’)soup.find_all(’tagName’):返回符合要求的所有標(biāo)簽(列表)select:select(’某種選擇器(id,class,標(biāo)簽...選擇器)’),返回的是一個列表。
2.層級選擇器:
soup.select(’.tang > ul > li > a’):>表示的是一個層級soup.select(’.tang > ul a’):空格表示的多個層級
3.獲取標(biāo)簽之間的文本數(shù)據(jù):
soup.a.text/string/get_text()text/get_text():可以獲取某一個標(biāo)簽中所有的文本內(nèi)容string:只可以獲取該標(biāo)簽下面直系的文本內(nèi)容
4.獲取標(biāo)簽中屬性值:
soup.a[’href’]
案例:爬取三國演義小說所有的章節(jié)標(biāo)題和章節(jié)內(nèi)容代碼如下:
import requestsfrom bs4 import BeautifulSoupif __name__ == '__main__': #對首頁的頁面數(shù)據(jù)進行爬取 headers = { ’User-Agent’: ’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’ } url = ’http://www.shicimingju.com/book/sanguoyanyi.html’ page_text = requests.get(url=url,headers=headers).text #在首頁中解析出章節(jié)的標(biāo)題和詳情頁的url #實例化BeautifulSoup對象,需要將頁面源碼數(shù)據(jù)加載到該對象中 soup = BeautifulSoup(page_text,’lxml’) #解析章節(jié)標(biāo)題和詳情頁的url li_list = soup.select(’.book-mulu > ul > li’) fp = open(’./sanguo.txt’,’w’,encoding=’utf-8’) for li in li_list: title = li.a.string detail_url = ’http://www.shicimingju.com’+li.a[’href’] #對詳情頁發(fā)起請求,解析出章節(jié)內(nèi)容 detail_page_text = requests.get(url=detail_url,headers=headers).text #解析出詳情頁中相關(guān)的章節(jié)內(nèi)容 detail_soup = BeautifulSoup(detail_page_text,’lxml’) div_tag = detail_soup.find(’div’,class_=’chapter_content’) #解析到了章節(jié)的內(nèi)容 content = div_tag.text fp.write(title+’:’+content+’n’) print(title,’爬取成功!!!’)
運行結(jié)果:
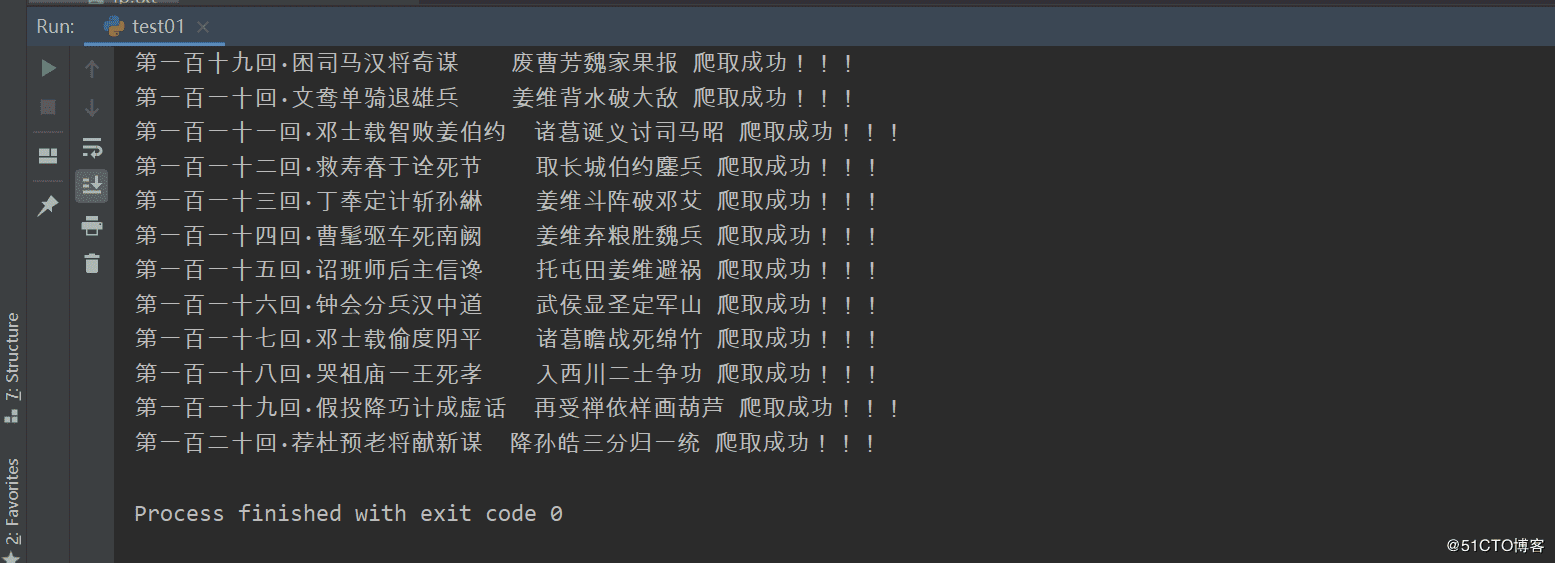

以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. python實現(xiàn)讀取類別頻數(shù)數(shù)據(jù)畫水平條形圖案例2. 使用css實現(xiàn)全兼容tooltip提示框3. python 爬取嗶哩嗶哩up主信息和投稿視頻4. ASP基礎(chǔ)入門第三篇(ASP腳本基礎(chǔ))5. 使用Spry輕松將XML數(shù)據(jù)顯示到HTML頁的方法6. PHP循環(huán)與分支知識點梳理7. CSS可以做的幾個令你嘆為觀止的實例分享8. CSS3實現(xiàn)動態(tài)翻牌效果 仿百度貼吧3D翻牌一次動畫特效9. ASP動態(tài)網(wǎng)頁制作技術(shù)經(jīng)驗分享10. jsp實現(xiàn)登錄驗證的過濾器
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備