python正則表達式的懶惰匹配和貪婪匹配說明
第一次碰到這個問題的時候,確實不知道該怎么辦,后來請教了一個大神,加上自己的理解,才了解是什么意思,這個東西寫python的會經常用到,而且會特別頻繁,在此寫一篇博客,希望可以幫到一些朋友。
例:一個字符串 “abcdacsdnd”
①懶惰匹配
regex = 'a.*?d'
②貪婪匹配
regex = 'a.*d'
測試代碼:
# coding=UTF-8import restr = 'abcdacsdn'print('原始字符串 ' + str)# 懶惰匹配regexL = 'a.*?d'print('懶惰匹配 = ' + regexL)regL = re.compile(regexL)listL = re.findall(regL, str)print('懶惰匹配結果')print(listL)# 貪婪匹配regexT = 'a.*d'print('貪婪匹配 = ' + regexT)regT = re.compile(regexT)listT = re.findall(regT, str)print('貪婪匹配結果')print(listT)
測試結果:
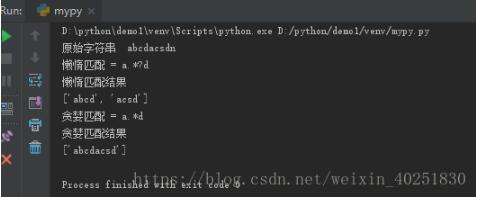
結果分析:
懶惰匹配,匹配成功兩次,一次abcd,一次acsd,匹配到滿足條件的abcd就停止了此次匹配,不會干擾后面的繼續匹配。
貪婪匹配,匹配成功一次,只有abcdacsd,匹配到字符串后,會最大限度的占用字符串
以上兩種,一個是盡量匹配最短串,一個是匹配最長串。
補充知識:python正則匹配中貪婪匹配效率比較
用例回歸完成之后,一般都要生成一個summary_report.但是,發現生成報告的時間耗時很久,搜集資料發現與匹配文件內容使用的正則表達式有很大關系.
1.匹配模式說明
下圖中圈住的部分,沒有注釋掉的使用貪婪匹配,注釋掉的使用非貪婪匹配
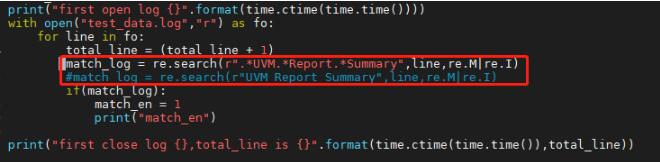
執行時間上二者差別巨大;另外執行時間與正則表達式的長度也有關系,較長的表達式建議分段匹配.
2.貪婪匹配時間

3.非貪婪匹配時間

以上這篇python正則表達式的懶惰匹配和貪婪匹配說明就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:
 網公網安備
網公網安備