從0到1使用python開(kāi)發(fā)一個(gè)半自動(dòng)答題小程序的實(shí)現(xiàn)
前言
最近每天都有玩微信讀書(shū)上面的每日一答的答題游戲,完全答對(duì)12題后,可以瓜分無(wú)限閱讀卡。但是從小就不太愛(ài)看書(shū)的我,很難連續(xù)答對(duì)12道題,由此,產(chǎn)生了寫(xiě)一個(gè)半自動(dòng)答題小程序的想法。我們先看一張效果圖吧(ps 這里主要是我電腦有點(diǎn)卡,點(diǎn)擊左邊地選項(xiàng)有延遲)
項(xiàng)目GIthub地址:微信讀書(shū)答題python小程序
覺(jué)得對(duì)你有幫助的請(qǐng)點(diǎn)個(gè)⭐來(lái)支持一下吧。
演示圖:
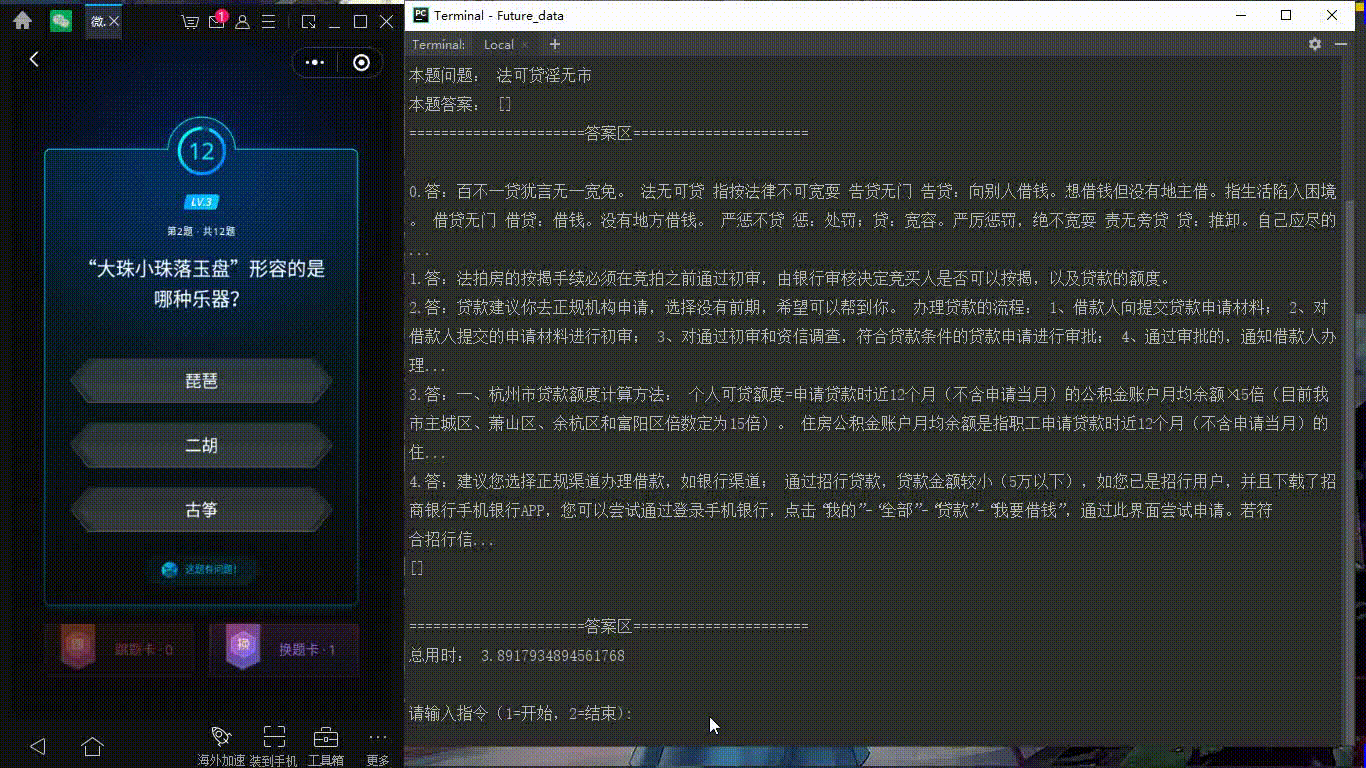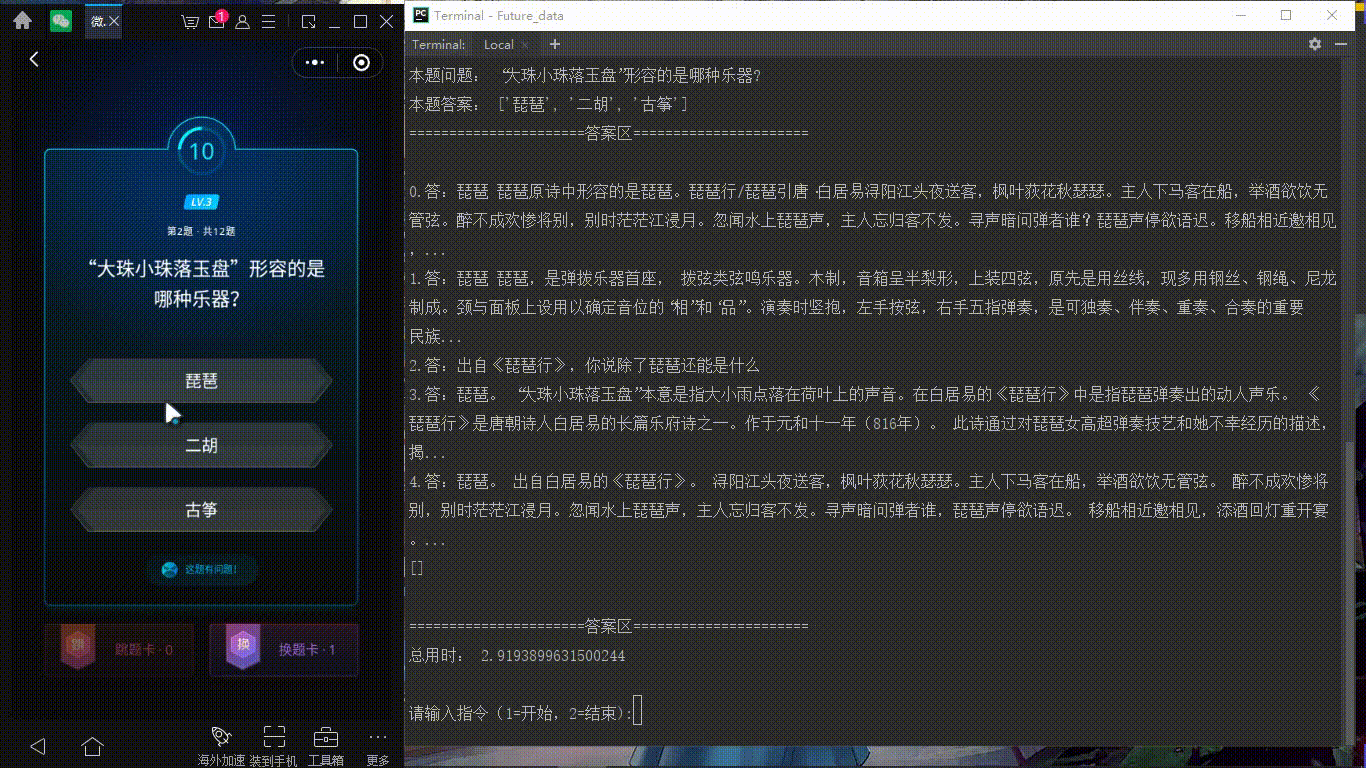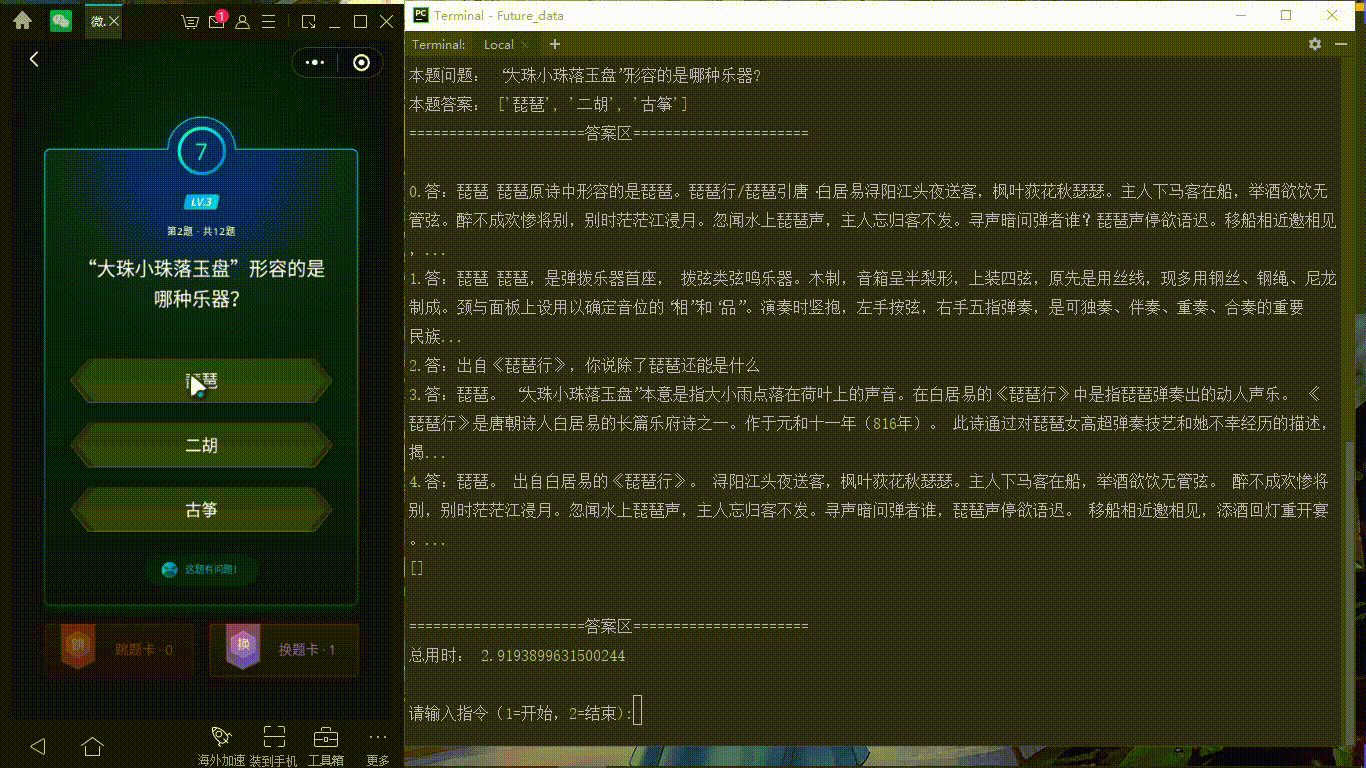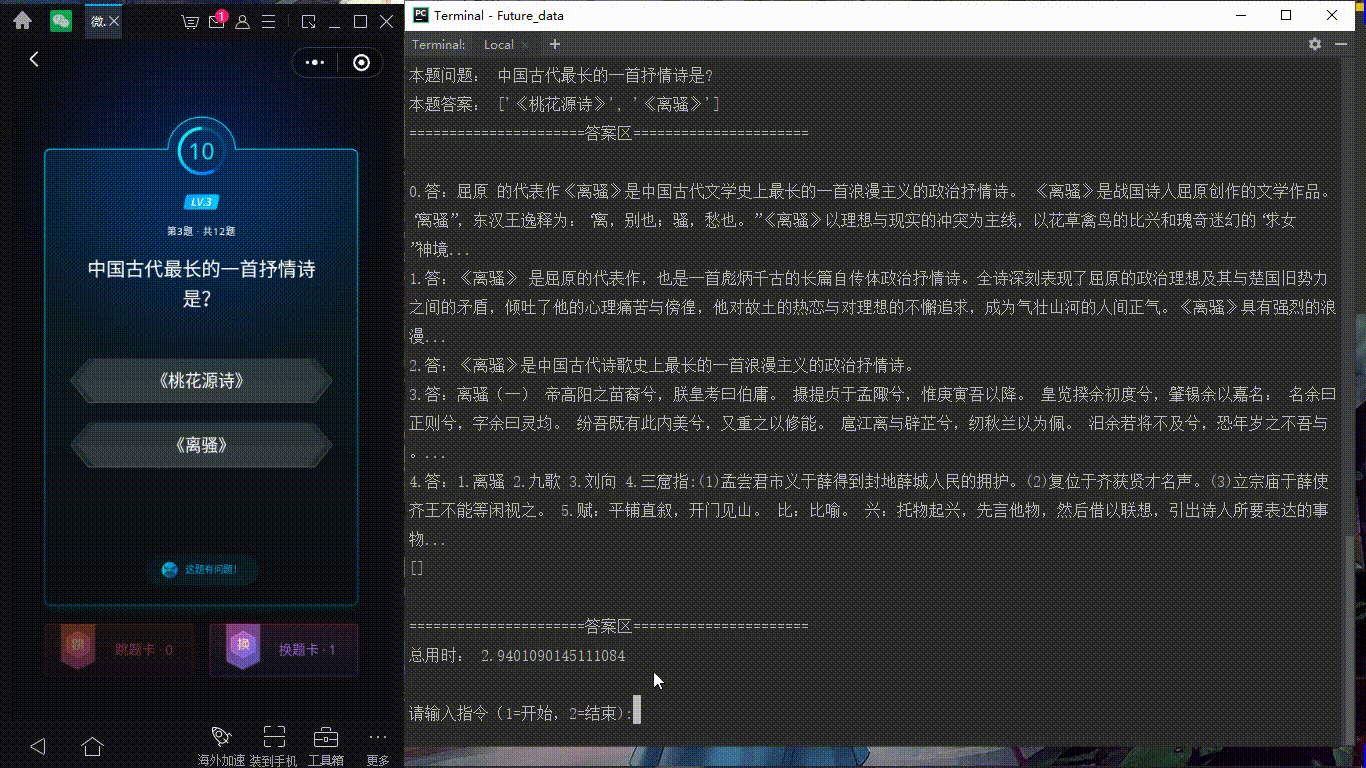
做前準(zhǔn)備
mumu模擬器 因?yàn)槭诌厸](méi)有安卓手機(jī),所以只能在模擬器上進(jìn)行模擬,如果手上有安卓手機(jī)地,可以適當(dāng)?shù)匦薷囊幌鲁绦颉P枰惭b微信和微信讀書(shū)這兩個(gè)軟件 python工具包:BeautifulSoup4、Pillow、urllib、requests、re、base64、time思路
截屏含有題目和答案的圖片(范圍可以自己指定) 使用百度的圖片識(shí)別技術(shù)將圖片轉(zhuǎn)化為文字,并進(jìn)行一系列處理,分別將題目和答案進(jìn)行存儲(chǔ) 調(diào)動(dòng)百度知道搜索接口,將題目作為搜索關(guān)鍵字進(jìn)行答案搜索 將搜索出來(lái)的內(nèi)容使用BeautifulSoup4進(jìn)行答案提取,這里可以設(shè)置答案提取數(shù)量 將搜索結(jié)果進(jìn)行輸出顯示附:這里我還加了一個(gè)自動(dòng)推薦答案,利用百度短文本相似接口和選項(xiàng)是否出現(xiàn)在答案中這兩種驗(yàn)證方法進(jìn)行驗(yàn)證,推薦相似度最高的答案。準(zhǔn)確度還可以,但是比較耗時(shí)間,比正常情況下時(shí)間要多上一倍。
開(kāi)始寫(xiě)代碼
1. 導(dǎo)入工具包
import requests #訪(fǎng)問(wèn)網(wǎng)站import re#正則表達(dá)式匹配import base64#編碼from bs4 import BeautifulSoup #處理頁(yè)面數(shù)據(jù)from urllib import parse #進(jìn)行url編碼import time #統(tǒng)計(jì)時(shí)間from PIL import ImageGrab #處理圖片
2. 編寫(xiě)類(lèi)和初始化方法
class autogetanswer(): def __init__(self,StartAutoRecomment=True,answernumber=5): self.StartAutoRecomment=StartAutoRecomment self.APIKEY=[’BICrxxxxxxxxNNI’,’CrHGxxxxxxxx3C’] self.SECRETKEY=[’BgL4jxxxxxxxxxGj9’,’1xo0jxxxxxx90cx’] self.accesstoken=[] self.baiduzhidao=’http://zhidao.baidu.com/search?’ self.question=’’ self.answer=[] self.answernumber=answernumber self.searchanswer=[] self.answerscore=[] self.reanswerindex=0 self.imageurl=’answer.jpg’ self.position=(35,155,355,680) self.titleregular1=r’(10題|共10|12題|共12|翻倍)’ self.titleregular2=r’(?|?)’ self.answerregular1=r’(這題|問(wèn)題|跳題|換題|題卡|換卡|跳卡|這有)’ self.StartAutoRecomment 是否開(kāi)啟自動(dòng)推薦答案,默認(rèn)為T(mén)rue self.APIKEY 百度圖像轉(zhuǎn)文字、百度短文本相似度分析 這兩個(gè)接口的apikey self.SECRETKEY 百度圖像轉(zhuǎn)文字、百度短文本相似度分析 這兩個(gè)接口的secretkey
這兩個(gè)key值我就沒(méi)法提供給大家了,大家可以自己去百度云官方申請(qǐng),免費(fèi)額度大概有5萬(wàn),足夠我們使用了。
申請(qǐng)過(guò)程大家可以參考這個(gè)博客,很簡(jiǎn)單的如何申請(qǐng)百度文字識(shí)別apikey和Secret Key
self.accesstoken 存儲(chǔ)申請(qǐng)使用接口的accesstoken值 self.baiduzhidao 百度知道搜索接口地址 self.imageurl 圖片地址 self.position 截圖方位信息,依次分別是左間距、上間距、右間距、下間距 self.titleregular1、.titleregular2、answerregular1 這些是進(jìn)行題目和答案處理的條件3. 獲得accesstoken值
def GetAccseetoken(self): for i in range(len(self.APIKEY)): host = ’https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}’.format(self.APIKEY[i],self.SECRETKEY[i]) response = requests.get(host) jsondata = response.json() self.accesstoken.append(jsondata[’access_token’])
這是官方提供的獲取accesstoken的摸板,大家直接使用就行了。
4. 圖像轉(zhuǎn)文字以及相關(guān)處理
def OCR(self,filename): request_url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic' # 二進(jìn)制方式打開(kāi)圖片文件 f = open(filename, ’rb’) img = base64.b64encode(f.read()) params = {'image':img} access_token = self.accesstoken[0] request_url = request_url + '?access_token=' + access_token headers = {’content-type’: ’application/x-www-form-urlencoded’} response = requests.post(request_url, data=params, headers=headers) #===上面是使用百度圖片轉(zhuǎn)文字接口轉(zhuǎn)化,返回格式為json if response: result = response.json() questionstart=0 answerstart=0 self.question=’’ self.answer=[] #確定題目和答案所在的位置 for i in range(result[’words_result_num’]):if(re.search(self.titleregular1,result[’words_result’][i][’words’])!=None): questionstart=i+1if(re.search(self.titleregular2,result[’words_result’][i][’words’])!=None): answerstart=i+1 #下面是進(jìn)行題目和答案的處理 if(answerstart!=0):for title in result[’words_result’][questionstart:answerstart]: if(re.search(self.answerregular1,title[’words’])!=None): pass else: self.question+=title[’words’]for answer in result[’words_result’][answerstart:]: if(re.search(self.answerregular1,answer[’words’])!=None): pass else: if(str(answer[’words’]).find(’.’)>0): answer2 = str(answer[’words’]).split(’.’)[-1] else: answer2=answer[’words’] self.answer.append(answer2) else:for title in result[’words_result’][questionstart:]: if(re.search(self.answerregular1,title[’words’])!=None): pass else: self.question+=title[’words’] print('本題問(wèn)題:',self.question) print('本題答案:',self.answer) return response.json()#可有可無(wú)
此方法是將圖片轉(zhuǎn)化為文字,進(jìn)行圖片中的文字識(shí)別,格式如下:
{ 'log_id': 2471272194, 'words_result_num': 2, 'words_result': [ {'words': ' TSINGTAO'}, {'words': '青?u睥酒'} ]}
下面我們以下面的圖為例,我們是如何去除掉干擾信息的:
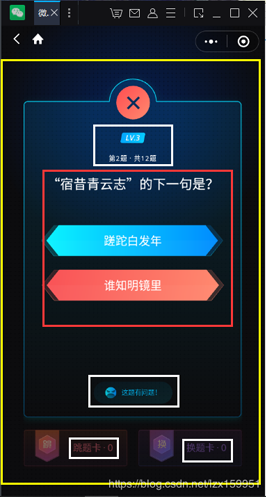
上圖就是程序在實(shí)際運(yùn)行中的情況,黃色框內(nèi)就是程序截取的圖像(這個(gè)通過(guò)初始化方法的參數(shù)中的position可以進(jìn)行設(shè)置),
我們需要的是紅色框內(nèi)的信息,這包含題目和答案選項(xiàng)。文字識(shí)別后,白色框里面的字也會(huì)和紅色框里的字一同被識(shí)別,并以json形式輸出,這些信息對(duì)我們就是干擾信息,所以,我通過(guò)建立了初始化方法里titleregular1、titleregular2、answerregular1 這三個(gè)標(biāo)準(zhǔn)進(jìn)行判定,白色框里的文字與對(duì)應(yīng),如果判斷包含的話(huà),就不添加到題目中或者答案中。
5. 百度知道進(jìn)行答案搜索
def BaiduAnswer(self): request = requests.session() headers={’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36’} data = {'word':self.question} url=self.baiduzhidao+’lm=0&rn=10&pn=0&fr=search&ie=gbk&’+parse.urlencode(data,encoding=’GB2312’) ress = request.get(url,headers=headers) ress.encoding=’gbk’ if ress: soup = BeautifulSoup(ress.text,’lxml’) result = soup.find_all('dd',class_='dd answer') if(len(result)!=0 and len(result)>self.answernumber):length=5 else:length=len(result) for i in range(length):self.searchanswer.append(result[i].text)
這里是模擬瀏覽器進(jìn)行百度知道搜索答案,將返回的文本交給BeautifulSoup進(jìn)行處理,提取出我們需要的部分。后面最后幾句有一個(gè)判定,如果查詢(xún)到的答案數(shù)量超過(guò)我們?cè)O(shè)置的答案數(shù),比如是5,那么就將前5個(gè)答案放入searchanswer列表中,如果查詢(xún)到的答案數(shù)量要少于我們?cè)O(shè)置的,返回所有答案。
6. 短文本相似度分析
def CalculateSimilarity(self,text1,text2): access_token = self.accesstoken[1] request_url='https://aip.baidubce.com/rpc/2.0/nlp/v2/simnet' request_url = request_url + '?access_token=' + access_token headers = {’Content-Type’: ’application/json’} data={'text_1':text1,'text_2':text2,'model':'GRNN'} response = requests.post(request_url, json=data, headers=headers) response.encoding=’gbk’ if response: try:result = response.json()return result[’score’] except:return 0
這里調(diào)用的是百度短文本相似度分析的接口,用于分析選項(xiàng)與查詢(xún)到的答案的相似度,以此來(lái)推薦一個(gè)參考答案。這個(gè)是官方給的摸板,直接調(diào)用,更換一下參數(shù)即可。
7. 自動(dòng)給出一個(gè)參考答案
def AutoRecomment(self): if(len(self.answer)==0): return for i in range(len(self.answer)): scores=[] flag=0 for j in range(len(self.searchanswer)):if(j!=0and (j%2==0)): time.sleep(0.1)score = tools.CalculateSimilarity(tools.answer[i],tools.searchanswer[j])if(tools.answer[i] in tools.searchanswer[j]): score=1scores.append(score)if(score>0.8): flag=1 self.answerscore.append(score) break if(flag==0):self.answerscore.append(max(scores)) self.reanswerindex = self.answerscore.index(max(self.answerscore))
這里調(diào)用了咱們第六步的CalculateSimilarity()方法,統(tǒng)計(jì)每一個(gè)選項(xiàng)與搜索到的答案相似度,取最高的存入answerscore列表中。這里我又加了一個(gè)操作,我發(fā)現(xiàn)這個(gè)相似度匹配有時(shí)正確率比較低,所以這里加了一個(gè)判定,若選項(xiàng)在搜索到的答案中出現(xiàn),給予一個(gè)最大相似值,也就是1,這就大大提高了推薦的準(zhǔn)確度。
8. 初始化參數(shù)
def IniParam(self): self.accesstoken=[] self.question=’’ self.answer=[] self.searchanswer=[] self.answerscore=[] self.reanswerindex=0
相關(guān)參數(shù)的初始化,因?yàn)槊窟M(jìn)行完一道題,要對(duì)存儲(chǔ)題和答案以及相關(guān)信息的數(shù)組進(jìn)行清空,否則會(huì)對(duì)后面題的顯示產(chǎn)生影響。
9. 主方法
def MainMethod(self): while(True): try:order = input(’請(qǐng)輸入指令(1=開(kāi)始,2=結(jié)束):’)if(int(order)==1): start = time.time() self.GetAccseetoken() img = ImageGrab.grab(self.position)#左、上、右、下 img.save(self.imageurl) self.OCR(self.imageurl) self.BaiduAnswer() if(self.StartAutoRecomment): self.AutoRecomment() print('======================答案區(qū)======================n') for i in range(len(self.searchanswer)): print('{}.{}'.format(i,self.searchanswer[i])) end = time.time() print(self.answerscore) if(self.StartAutoRecomment and len(self.answer)>0): print('n推薦答案:',self.answer[self.reanswerindex]) print('n======================答案區(qū)======================') print('總用時(shí):',end-start,end='nn') self.IniParam()else: break except:print('識(shí)別失敗,請(qǐng)重新嘗試')self.IniParam()pass
這里主要是一個(gè)while循環(huán),通過(guò)輸入指定來(lái)判斷是否結(jié)束循環(huán)。
這里說(shuō)一下下面這兩個(gè)語(yǔ)句:
img = ImageGrab.grab(self.position)#左、上、右、下img.save(self.imageurl)
這兩個(gè)語(yǔ)句是用來(lái)截取我們指定位置的圖片,然后進(jìn)行圖片的保存。
總結(jié)
上述呢,就是整個(gè)項(xiàng)目完成的流程,整體運(yùn)行是幾乎每什么問(wèn)題,但是還是存在許多可優(yōu)化的空間。也歡迎大家對(duì)此感興趣的留言,說(shuō)說(shuō)你的改進(jìn)意見(jiàn),我會(huì)非常感謝,并認(rèn)真考慮進(jìn)去。期待與大家的討論!😄
到此這篇關(guān)于從0到1使用python開(kāi)發(fā)一個(gè)半自動(dòng)答題小程序的實(shí)現(xiàn)的文章就介紹到這了,更多相關(guān)python 半自動(dòng)答題小程序內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. python爬蟲(chóng)beautifulsoup解析html方法2. Python 如何將integer轉(zhuǎn)化為羅馬數(shù)(3999以?xún)?nèi))3. python 實(shí)現(xiàn)aes256加密4. 詳解Python模塊化編程與裝飾器5. css進(jìn)階學(xué)習(xí) 選擇符6. Python性能測(cè)試工具Locust安裝及使用7. 以PHP代碼為實(shí)例詳解RabbitMQ消息隊(duì)列中間件的6種模式8. 使用Python解析Chrome瀏覽器書(shū)簽的示例9. html小技巧之td,div標(biāo)簽里內(nèi)容不換行10. python web框架的總結(jié)
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備