淺談Python中re.match()和re.search()的使用及區(qū)別
1.re.match()
re.match()的概念是從頭匹配一個(gè)符合規(guī)則的字符串,從起始位置開始匹配,匹配成功返回一個(gè)對(duì)象,未匹配成功返回None。
包含的參數(shù)如下:
pattern: 正則模型
string : 要匹配的字符串
falgs : 匹配模式
match() 方法一旦匹配成功,就是一個(gè)match object對(duì)象,而match object對(duì)象有以下方法:
group() 返回被 RE 匹配的字符串
start() 返回匹配開始的位置
end() 返回匹配結(jié)束的位置
span()返回一個(gè)元組包含匹配 (開始,結(jié)束) 的位置
案例:
import re# re.match 返回一個(gè)Match Object 對(duì)象# 對(duì)象提供了 group() 方法,來獲取匹配的結(jié)果result = re.match('hello','hello,world')if result: print(result.group())else: print('匹配失敗!')
輸出結(jié)果:
hello
2.re.search()
re.search()函數(shù)會(huì)在字符串內(nèi)查找模式匹配,只要找到第一個(gè)匹配然后返回,如果字符串沒有匹配,則返回None。
格式:re.search(pattern, string, flags=0)
要求:匹配出文章閱讀的次數(shù)
import reret = re.search(r'd+', '閱讀次數(shù)為 9999')print(ret.group())
輸出結(jié)果:
9999
3.match()和search()的區(qū)別:
match()函數(shù)只檢測(cè)RE是不是在string的開始位置匹配,
search()會(huì)掃描整個(gè)string查找匹配
match()只有在0位置匹配成功的話才有返回,如果不是開始位置匹配成功的話,match()就返回none
舉例說明:
import reprint(re.match(’super’, ’superstition’).span())
(0, 5)
print(re.match(’super’,’insuperable’))
None
print(re.search(’super’,’superstition’).span())
(0, 5)
print(re.search(’super’,’insuperable’).span())
(2, 7)
補(bǔ)充知識(shí): jupyter notebook_主函數(shù)文件如何調(diào)用類文件
使用jupyter notebook編寫python程序,rw_visual.jpynb是寫的主函數(shù),random_walk.jpynb是類(如圖)。在主函數(shù)中將類實(shí)例化后運(yùn)行會(huì)報(bào)錯(cuò),經(jīng)網(wǎng)絡(luò)查找解決了問題,缺少Ipynb_importer.py這樣一個(gè)鏈接文件。
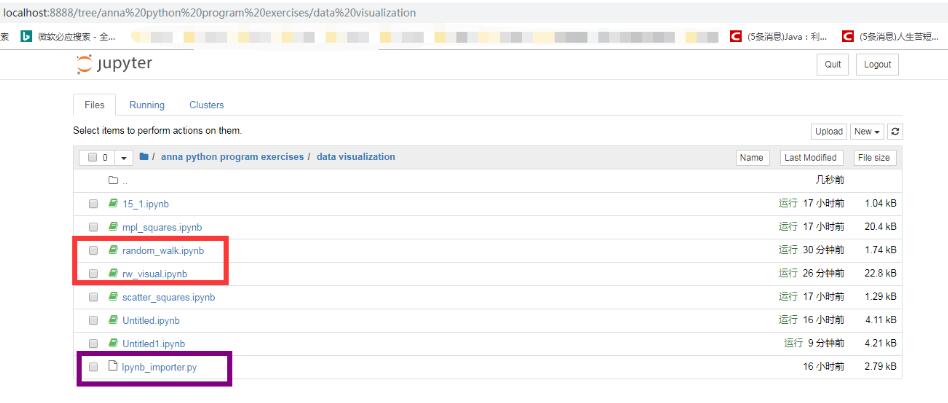
解決方法:
1、在同一路徑下創(chuàng)建名為Ipynb_importer.py的文件:File-->download as-->Python(.py),該文件內(nèi)容如下:
#!/usr/bin/env python# coding: utf-8# In[ ]: import io, os,sys,typesfrom IPython import get_ipythonfrom nbformat import readfrom IPython.core.interactiveshell import InteractiveShell class NotebookFinder(object): '''Module finder that locates Jupyter Notebooks''' def __init__(self): self.loaders = {} def find_module(self, fullname, path=None): nb_path = find_notebook(fullname, path) if not nb_path: return key = path if path: # lists aren’t hashable key = os.path.sep.join(path) if key not in self.loaders: self.loaders[key] = NotebookLoader(path) return self.loaders[key] def find_notebook(fullname, path=None): '''find a notebook, given its fully qualified name and an optional path This turns 'foo.bar' into 'foo/bar.ipynb' and tries turning 'Foo_Bar' into 'Foo Bar' if Foo_Bar does not exist. ''' name = fullname.rsplit(’.’, 1)[-1] if not path: path = [’’] for d in path: nb_path = os.path.join(d, name + '.ipynb') if os.path.isfile(nb_path): return nb_path # let import Notebook_Name find 'Notebook Name.ipynb' nb_path = nb_path.replace('_', ' ') if os.path.isfile(nb_path): return nb_path class NotebookLoader(object): '''Module Loader for Jupyter Notebooks''' def __init__(self, path=None): self.shell = InteractiveShell.instance() self.path = path def load_module(self, fullname): '''import a notebook as a module''' path = find_notebook(fullname, self.path) print ('importing Jupyter notebook from %s' % path) # load the notebook object with io.open(path, ’r’, encoding=’utf-8’) as f: nb = read(f, 4) # create the module and add it to sys.modules # if name in sys.modules: # return sys.modules[name] mod = types.ModuleType(fullname) mod.__file__ = path mod.__loader__ = self mod.__dict__[’get_ipython’] = get_ipython sys.modules[fullname] = mod # extra work to ensure that magics that would affect the user_ns # actually affect the notebook module’s ns save_user_ns = self.shell.user_ns self.shell.user_ns = mod.__dict__ try: for cell in nb.cells: if cell.cell_type == ’code’:# transform the input to executable Pythoncode = self.shell.input_transformer_manager.transform_cell(cell.source)# run the code in themoduleexec(code, mod.__dict__) finally: self.shell.user_ns = save_user_ns return modsys.meta_path.append(NotebookFinder())
2、在主函數(shù)中import Ipynb_importer
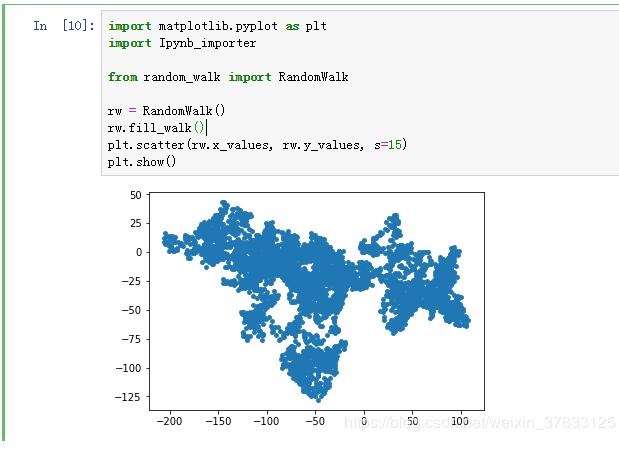
import matplotlib.pyplot as pltimport Ipynb_importer from random_walk import RandomWalk rw = RandomWalk()rw.fill_walk()plt.scatter(rw.x_values, rw.y_values, s=15)plt.show()
3、運(yùn)行主函數(shù),調(diào)用成功
ps:random_walk.jpynb文件內(nèi)容如下:
from random import choice class RandomWalk(): def __init__(self, num_points=5000): self.num_points = num_points self.x_values = [0] self.y_values = [0] def fill_walk(self): while len(self.x_values) < self.num_points: x_direction = choice([1,-1]) x_distance = choice([0,1,2,3,4]) x_step = x_direction * x_distance y_direction = choice([1,-1]) y_distance = choice([0,1,2,3,4]) y_step = y_direction * y_distance if x_step == 0 and y_step == 0:continue next_x = self.x_values[-1] + x_step next_y = self.y_values[-1] + y_step self.x_values.append(next_x) self.y_values.append(next_y)
運(yùn)行結(jié)果:
以上這篇淺談Python中re.match()和re.search()的使用及區(qū)別就是小編分享給大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. jsp網(wǎng)頁實(shí)現(xiàn)貪吃蛇小游戲2. jsp+servlet簡(jiǎn)單實(shí)現(xiàn)上傳文件功能(保存目錄改進(jìn))3. JavaScript實(shí)現(xiàn)組件化和模塊化方法詳解4. ASP.NET MVC遍歷驗(yàn)證ModelState的錯(cuò)誤信息5. HTML5 Canvas繪制圖形從入門到精通6. .Net Core和RabbitMQ限制循環(huán)消費(fèi)的方法7. 淺談SpringMVC jsp前臺(tái)獲取參數(shù)的方式 EL表達(dá)式8. SpringMVC+Jquery實(shí)現(xiàn)Ajax功能9. ASP中if語句、select 、while循環(huán)的使用方法10. asp(vbs)Rs.Open和Conn.Execute的詳解和區(qū)別及&H0001的說明
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備