python sklearn包——混淆矩陣、分類報(bào)告等自動生成方式
preface:做著最近的任務(wù),對數(shù)據(jù)處理,做些簡單的提特征,用機(jī)器學(xué)習(xí)算法跑下程序得出結(jié)果,看看哪些特征的組合較好,這一系列流程必然要用到很多函數(shù),故將自己常用函數(shù)記錄上。應(yīng)該說這些函數(shù)基本上都會用到,像是數(shù)據(jù)預(yù)處理,處理完了后特征提取、降維、訓(xùn)練預(yù)測、通過混淆矩陣看分類效果,得出報(bào)告。
1.輸入
從數(shù)據(jù)集開始,提取特征轉(zhuǎn)化為有標(biāo)簽的數(shù)據(jù)集,轉(zhuǎn)為向量。拆分成訓(xùn)練集和測試集,這里不多講,在上一篇博客中談到用StratifiedKFold()函數(shù)即可。在訓(xùn)練集中有data和target開始。
2.處理
def my_preprocessing(train_data): from sklearn import preprocessing X_normalized = preprocessing.normalize(train_data ,norm = 'l2',axis=0)#使用l2范式,對特征列進(jìn)行正則 return X_normalized def my_feature_selection(data, target): from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 data_new = SelectKBest(chi2, k= 50).fit_transform(data,target) return data_new def my_PCA(data):#data without target, just train data, withou train target. from sklearn import decomposition pca_sklearn = decomposition.PCA() pca_sklearn.fit(data) main_var = pca_sklearn.explained_variance_ print sum(main_var)*0.9 import matplotlib.pyplot as plt n = 15 plt.plot(main_var[:n]) plt.show() def clf_train(data,target): from sklearn import svm #from sklearn.linear_model import LogisticRegression clf = svm.SVC(C=100,kernel='rbf',gamma=0.001) clf.fit(data,target) #clf_LR = LogisticRegression() #clf_LR.fit(x_train, y_train) #y_pred_LR = clf_LR.predict(x_test) return clf def my_confusion_matrix(y_true, y_pred): from sklearn.metrics import confusion_matrix labels = list(set(y_true)) conf_mat = confusion_matrix(y_true, y_pred, labels = labels) print 'confusion_matrix(left labels: y_true, up labels: y_pred):' print 'labelst', for i in range(len(labels)): print labels[i],'t', print for i in range(len(conf_mat)): print i,'t', for j in range(len(conf_mat[i])): print conf_mat[i][j],’t’, print print def my_classification_report(y_true, y_pred): from sklearn.metrics import classification_report print 'classification_report(left: labels):' print classification_report(y_true, y_pred)
my_preprocess()函數(shù):
主要使用sklearn的preprocessing函數(shù)中的normalize()函數(shù),默認(rèn)參數(shù)為l2范式,對特征列進(jìn)行正則處理。即每一個(gè)樣例,處理標(biāo)簽,每行的平方和為1.
my_feature_selection()函數(shù):
使用sklearn的feature_selection函數(shù)中SelectKBest()函數(shù)和chi2()函數(shù),若是用詞袋提取了很多維的稀疏特征,有必要使用卡方選取前k個(gè)有效的特征。
my_PCA()函數(shù):
主要用來觀察前多少個(gè)特征是主要特征,并且畫圖。看看前多少個(gè)特征占據(jù)主要部分。
clf_train()函數(shù):
可用多種機(jī)器學(xué)習(xí)算法,如SVM, LR, RF, GBDT等等很多,其中像SVM需要調(diào)參數(shù)的,有專門調(diào)試參數(shù)的函數(shù)如StratifiedKFold()(見前幾篇博客)。以達(dá)到最優(yōu)。
my_confusion_matrix()函數(shù):
主要是針對預(yù)測出來的結(jié)果,和原來的結(jié)果對比,算出混淆矩陣,不必自己計(jì)算。其對每個(gè)類別的混淆矩陣都計(jì)算出來了,并且labels參數(shù)默認(rèn)是排序了的。
my_classification_report()函數(shù):
主要通過sklearn.metrics函數(shù)中的classification_report()函數(shù),針對每個(gè)類別給出詳細(xì)的準(zhǔn)確率、召回率和F-值這三個(gè)參數(shù)和宏平均值,用來評價(jià)算法好壞。另外ROC曲線的話,需要是對二分類才可以。多類別似乎不行。
主要參考sklearn官網(wǎng)
補(bǔ)充拓展:[sklearn] 混淆矩陣——多分類預(yù)測結(jié)果統(tǒng)計(jì)
調(diào)用的函數(shù):confusion_matrix(typeTrue, typePred)
typeTrue:實(shí)際類別,list類型
typePred:預(yù)測類別,list類型
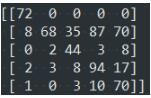
結(jié)果如下面的截圖:
第i行:實(shí)際為第i類,預(yù)測到各個(gè)類的樣本數(shù)
第j列:預(yù)測為第j類,實(shí)際為各個(gè)類的樣本數(shù)
true↓ predict→
以上這篇python sklearn包——混淆矩陣、分類報(bào)告等自動生成方式就是小編分享給大家的全部內(nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. ajax請求添加自定義header參數(shù)代碼2. ASP基礎(chǔ)知識VBScript基本元素講解3. Python requests庫參數(shù)提交的注意事項(xiàng)總結(jié)4. IntelliJ IDEA導(dǎo)入jar包的方法5. Gitlab CI-CD自動化部署SpringBoot項(xiàng)目的方法步驟6. Kotlin + Flow 實(shí)現(xiàn)Android 應(yīng)用初始化任務(wù)啟動庫7. 利用CSS3新特性創(chuàng)建透明邊框三角8. python爬蟲學(xué)習(xí)筆記之pyquery模塊基本用法詳解9. ASP中解決“對象關(guān)閉時(shí),不允許操作。”的詭異問題……10. python操作mysql、excel、pdf的示例

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備