Java基礎(chǔ)之MapReduce框架總結(jié)與擴(kuò)展知識(shí)點(diǎn)
MapTask就是Map階段的job,它的數(shù)量由切片決定
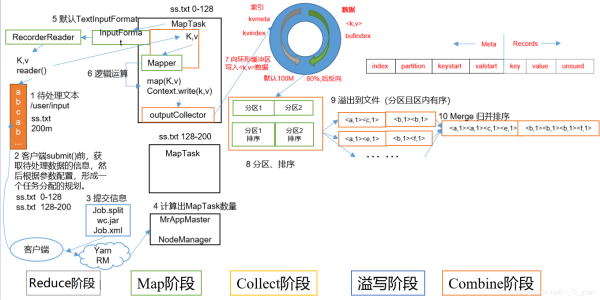
1.Read階段:讀取文件,此時(shí)進(jìn)行對(duì)文件數(shù)據(jù)進(jìn)行切片(InputFormat進(jìn)行切片),通過(guò)切片,從而確定MapTask的數(shù)量,切片中包含數(shù)據(jù)和key(偏移量)
2.Map階段:這個(gè)階段是針對(duì)數(shù)據(jù)進(jìn)行map方法的計(jì)算操作,通過(guò)該方法,可以對(duì)切片中的key和value進(jìn)行處理
3.Collect收集階段:在用戶編寫map()函數(shù)中,當(dāng)數(shù)據(jù)處理完成后,一般會(huì)調(diào)用OutputCollector.collect()輸出結(jié)果。在該函數(shù)內(nèi)部,它會(huì)將生成的key/value分區(qū)(調(diào)用Partitioner),并寫入一個(gè)環(huán)形內(nèi)存緩沖區(qū)中。
4.Spill階段:即“溢寫”,當(dāng)環(huán)形緩沖區(qū)滿后,MapReduce會(huì)將數(shù)據(jù)寫到本地磁盤上,生成一個(gè)臨時(shí)文件。需要注意的是,將數(shù)據(jù)寫入本地磁盤之前,先要對(duì)數(shù)據(jù)進(jìn)行一次本地排序,并在必要時(shí)對(duì)數(shù)據(jù)進(jìn)行合并、壓縮等操作。
5.Combine階段:當(dāng)所有數(shù)據(jù)處理完成后,MapTask對(duì)所有臨時(shí)文件進(jìn)行一次合并,以確保最終只會(huì)生成一個(gè)數(shù)據(jù)文件,這個(gè)階段默認(rèn)是沒(méi)有的,一般需要我們自定義
6.當(dāng)所有數(shù)據(jù)處理完后,MapTask會(huì)將所有臨時(shí)文件合并成一個(gè)大文件,并保存到文件output/file.out中,同時(shí)生成相應(yīng)的索引文件output/file.out.index。
7.在進(jìn)行文件合并過(guò)程中,MapTask以分區(qū)為單位進(jìn)行合并。對(duì)于某個(gè)分區(qū),它將采用多輪遞歸合并的方式。每輪合并io.sort.factor(默認(rèn)10)個(gè)文件,并將產(chǎn)生的文件重新加入待合并列表中,對(duì)文件排序后,重復(fù)以上過(guò)程,直到最終得到一個(gè)大文件。
8.讓每個(gè)MapTask最終只生成一個(gè)數(shù)據(jù)文件,可避免同時(shí)打開(kāi)大量文件和同時(shí)讀取大量小文件產(chǎn)生的隨機(jī)讀取帶來(lái)的開(kāi)銷
第四步溢寫階段詳情:
步驟1:利用快速排序算法對(duì)緩存區(qū)內(nèi)的數(shù)據(jù)進(jìn)行排序,排序方式是,先按照分區(qū)編號(hào)Partition進(jìn)行排序,然后按照key進(jìn)行排序。這樣,經(jīng)過(guò)排序后,數(shù)據(jù)以分區(qū)為單位聚集在一起,且同一分區(qū)內(nèi)所有數(shù)據(jù)按照key有序。 步驟2:按照分區(qū)編號(hào)由小到大依次將每個(gè)分區(qū)中的數(shù)據(jù)寫入任務(wù)工作目錄下的臨時(shí)文件output/spillN.out(N表示當(dāng)前溢寫次數(shù))中。如果用戶設(shè)置了Combiner,則寫入文件之前,對(duì)每個(gè)分區(qū)中的數(shù)據(jù)進(jìn)行一次聚集操作。 步驟3:將分區(qū)數(shù)據(jù)的元信息寫到內(nèi)存索引數(shù)據(jù)結(jié)構(gòu)SpillRecord中,其中每個(gè)分區(qū)的元信息包括在臨時(shí)文件中的偏移量、壓縮前數(shù)據(jù)大小和壓縮后數(shù)據(jù)大小。如果當(dāng)前內(nèi)存索引大小超過(guò)1MB,則將內(nèi)存索引寫到文件output/spillN.out.index中。三、ReduceTask工作機(jī)制ReduceTask就是Reduce階段的job,它的數(shù)量由Map階段的分區(qū)進(jìn)行決定
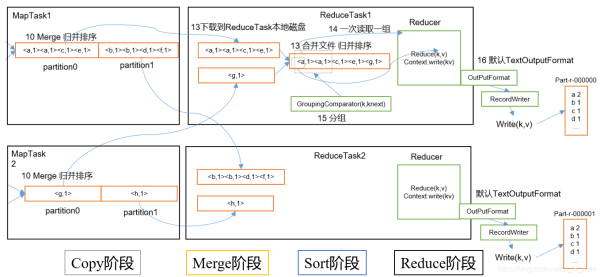
1.Copy階段:ReduceTask從各個(gè)MapTask上遠(yuǎn)程拷貝一片數(shù)據(jù),并針對(duì)某一片數(shù)據(jù),如果其大小超過(guò)一定閾值,則寫到磁盤上,否則直接放到內(nèi)存中。
2.Merge階段:在遠(yuǎn)程拷貝數(shù)據(jù)的同時(shí),ReduceTask啟動(dòng)了兩個(gè)后臺(tái)線程對(duì)內(nèi)存和磁盤上的文件進(jìn)行合并,以防止內(nèi)存使用過(guò)多或磁盤上文件過(guò)多。
3.Sort階段:按照MapReduce語(yǔ)義,用戶編寫reduce()函數(shù)輸入數(shù)據(jù)是按key進(jìn)行聚集的一組數(shù)據(jù)。為了將key相同的數(shù)據(jù)聚在一起,Hadoop采用了基于排序的策略。由于各個(gè)MapTask已經(jīng)實(shí)現(xiàn)對(duì)自己的處理結(jié)果進(jìn)行了局部排序,因此,ReduceTask只需對(duì)所有數(shù)據(jù)進(jìn)行一次歸并排序即可。
4.Reduce階段:reduce()函數(shù)將計(jì)算結(jié)果寫到HDFS上
五、數(shù)據(jù)清洗(ETL)我們?cè)诖髷?shù)據(jù)開(kāi)篇概述中說(shuō)過(guò),數(shù)據(jù)是低價(jià)值的,所以我們要從海量數(shù)據(jù)中獲取到我們想要的數(shù)據(jù),首先就需要對(duì)數(shù)據(jù)進(jìn)行清洗,這個(gè)過(guò)程也稱之為ETL
還記得上一章中的Join案例么,我們對(duì)pname字段的填充,也算數(shù)據(jù)清洗的一種,下面我通過(guò)一個(gè)簡(jiǎn)單的案例來(lái)演示一下數(shù)據(jù)清洗
數(shù)據(jù)清洗案例
需求:過(guò)濾一下log日志中字段個(gè)數(shù)小于11的日志(隨便舉個(gè)栗子而已)
測(cè)試數(shù)據(jù):就拿我們這兩天學(xué)習(xí)中HadoopNodeName產(chǎn)生的日志來(lái)當(dāng)測(cè)試數(shù)據(jù)吧,我將log日志信息放到我的windows中,數(shù)據(jù)位置如下
/opt/module/hadoop-3.1.3/logs/hadoop-xxx-nodemanager-hadoop102.log
編寫思路:
直接通過(guò)切片,然后判斷長(zhǎng)度即可,因?yàn)槭桥e個(gè)栗子,沒(méi)有那么復(fù)雜
真正的數(shù)據(jù)清洗會(huì)使用框架來(lái)做,這個(gè)我后面會(huì)為大家?guī)?lái)相關(guān)的知識(shí)
ETLDriverpackage com.company.etl;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class ETLDriver { public static void main(String[] args) throws Exception {Job job = Job.getInstance(new Configuration());job.setJarByClass(ETLDriver.class);job.setMapperClass(ETLMapper.class);job.setNumReduceTasks(0);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job,new Path('D:ioinput8'));FileOutputFormat.setOutputPath(job,new Path('D:iooutput88'));job.waitForCompletion(true); }} ETLMapper
package com.company.etl;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Counter;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//清洗(過(guò)濾)String line = value.toString();String[] info = line.split(' ');//判斷if (info.length > 11){ context.write(value,NullWritable.get());} }}六、計(jì)數(shù)器應(yīng)用 顧名思義,計(jì)數(shù)器的作用就是用于計(jì)數(shù)的,在Hadoop中,它內(nèi)部也有一個(gè)計(jì)數(shù)器,用于監(jiān)控統(tǒng)計(jì)我們處理數(shù)據(jù)的數(shù)量 我們通常在MapReduce中通過(guò)上下文 context進(jìn)行應(yīng)用,例如在Mapper中,我通過(guò)step方法進(jìn)行初始化計(jì)數(shù)器,然后在我們map方法中進(jìn)行計(jì)數(shù)七、計(jì)數(shù)器案例
在上面數(shù)據(jù)清洗的基礎(chǔ)上進(jìn)行計(jì)數(shù)器的使用,Driver沒(méi)什么變化,只有Mapper
我們?cè)贛apper的setup方法中,創(chuàng)建計(jì)數(shù)器的對(duì)象,然后在map方法中調(diào)用它即可
ETLMapper
package com.company.etl;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Counter;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable> { private Counter sucess; private Counter fail; /*創(chuàng)建計(jì)數(shù)器對(duì)象 */ @Override protected void setup(Context context) throws IOException, InterruptedException {/* getCounter(String groupName, String counterName); 第一個(gè)參數(shù) :組名 隨便寫 第二個(gè)參數(shù) :計(jì)數(shù)器名 隨便寫 */sucess = context.getCounter('ETL', 'success');fail = context.getCounter('ETL', 'fail'); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//清洗(過(guò)濾)String line = value.toString();String[] info = line.split(' ');//判斷if (info.length > 11){ context.write(value,NullWritable.get()); //統(tǒng)計(jì) sucess.increment(1);}else{ fail.increment(1);} }}八、MapReduce總結(jié)
好了,到這里,我們MapReduce就全部學(xué)習(xí)完畢了,接下來(lái),我再把整個(gè)內(nèi)容串一下,還是MapReduce的那個(gè)圖
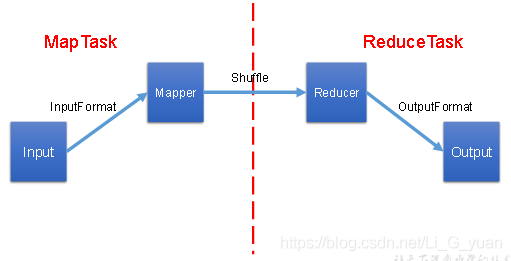
MapReduce的主要工作就是對(duì)數(shù)據(jù)進(jìn)行運(yùn)算、分析,它的工作流程如下:
1.我們會(huì)將HDFS中的數(shù)據(jù)通過(guò)InputFormat進(jìn)行進(jìn)行讀取、切片,從而計(jì)算出MapTask的數(shù)量
2.每一個(gè)MapTask中都會(huì)有Mapper類,里面的map方法就是任務(wù)的具體實(shí)現(xiàn),我們通過(guò)它,可以完成數(shù)據(jù)的key,value封裝,然后通過(guò)分區(qū)進(jìn)入shuffle中來(lái)完成每個(gè)MapTask中的數(shù)據(jù)分區(qū)排序
3.通過(guò)分區(qū)來(lái)決定ReduceTask的數(shù)量,每一個(gè)ReduceTask都有一個(gè)Reducer類,里面的reduce方法是ReduceTask的具體實(shí)現(xiàn),它主要是完成最后的數(shù)據(jù)合并工作
4.當(dāng)Reduce任務(wù)過(guò)重,我們可以通過(guò)Combiner合并,在Mapper階段來(lái)進(jìn)行局部的數(shù)據(jù)合并,減輕Reduce的任務(wù)量,當(dāng)然,前提是Combiner所做的局部合并工作不會(huì)影響最終的結(jié)果
5.當(dāng)Reducer的任務(wù)完成,會(huì)將最終的key,value寫出,交給OutputFormat,用于數(shù)據(jù)的寫出,通過(guò)OutputFormat來(lái)完成HDFS的寫入操作
每一個(gè)MapTask和ReduceTask內(nèi)部都是循環(huán)進(jìn)行讀取,并且它有三個(gè)方法:setup() map()/reduce() cleanup()setup()方法是在MapTask/ReduceTask剛剛啟動(dòng)時(shí)進(jìn)行調(diào)用,cleanup()是在任務(wù)完成后調(diào)用
到此這篇關(guān)于Java基礎(chǔ)之MapReduce框架總結(jié)與擴(kuò)展知識(shí)點(diǎn)的文章就介紹到這了,更多相關(guān)Java MapReduce框架內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Gitlab CI-CD自動(dòng)化部署SpringBoot項(xiàng)目的方法步驟2. Idea 快速生成方法返回值的操作3. 基于javascript處理二進(jìn)制圖片流過(guò)程詳解4. Docker 部署 Prometheus的安裝詳細(xì)教程5. 使用Python和百度語(yǔ)音識(shí)別生成視頻字幕的實(shí)現(xiàn)6. ajax請(qǐng)求添加自定義header參數(shù)代碼7. idea開(kāi)啟代碼提示功能的方法步驟8. idea刪除項(xiàng)目的操作方法9. JAVA上加密算法的實(shí)現(xiàn)用例10. JS sort方法基于數(shù)組對(duì)象屬性值排序

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備