詳解python中文編碼問題
在Python中有兩種默認(rèn)的字符串:str和unicode。在Python中一定要注意區(qū)分“Unicode字符串”和“unicode對(duì)象”的區(qū)別。后面所有的“unicode字符串”指的都是python里的“unicode對(duì)象”。
事實(shí)上在Python中并沒有“Unicode字符串”這樣的東西,只有“unicode”對(duì)象。一個(gè)傳統(tǒng)意義上的unicode字符串完全可以用str對(duì)象表示。只是這時(shí)候它僅僅是一個(gè)字節(jié)流,除非解碼為unicode對(duì)象,沒有任何實(shí)際的意義。
我們用“哈哈”在多個(gè)平臺(tái)上測(cè)試,其中“哈”對(duì)應(yīng)的不同編碼是:
1. UNICODE (UTF8-16), C854;
2. UTF-8, E59388;
3. GBK, B9FE。
1.1 Windows控制臺(tái)下面是在windows控制臺(tái)的運(yùn)行結(jié)果:
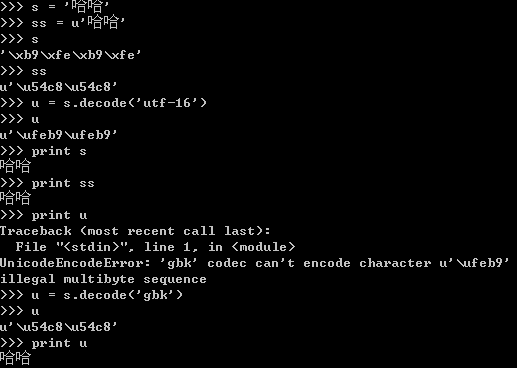
可以看出在控制臺(tái),中文字符的編碼是GBK而不是UTF-16。將字符串s(GBK編碼)使用decode進(jìn)行解碼后,可以得到同等的unicode對(duì)象。
注意:可以在控制臺(tái)打印ss并不代表它可以直接被序列化,比如:

向文件直接輸出ss會(huì)拋出同樣的異常。在處理unicode中文字符串的時(shí)候,必須首先對(duì)它調(diào)用encode函數(shù),轉(zhuǎn)換成其它編碼輸出。這一點(diǎn)對(duì)各個(gè)環(huán)境都一樣。
總結(jié):在Python中,“str”對(duì)象就是一個(gè)字節(jié)數(shù)組,至于里面的內(nèi)容是不是一個(gè)合法的字符串,以及這個(gè)字符串采用什么編碼(gbk, utf-8, unicode)都不重要。這些內(nèi)容需要用戶自己記錄和判斷。這些的限制也同樣適用于“unicode”對(duì)象。要記住“unicode”對(duì)象中的內(nèi)容可絕對(duì)不一定就是合法的unicode字符串,我們很快就會(huì)看到這種情況。
總結(jié):在windows的控制臺(tái)上,支持gbk編碼的str對(duì)象和unicode編碼的unicode對(duì)象。
1.2 Windows IDLE(在Shell上運(yùn)行)在windows下的IDLE中,運(yùn)行效果和windows控制臺(tái)不完全一致:

可以看出,對(duì)于不使用“u”作標(biāo)識(shí)的字符串,IDLE把其中的中文字符進(jìn)行GBK編碼。但是對(duì)于使用“u”的unicode字符串,IDLE居然一樣是用了GBK編碼,不同的是,這時(shí)候每一個(gè)字符都是unicode(對(duì)象)字符!!此時(shí)len(ss) = 4。
這樣產(chǎn)生了一個(gè)神奇的問題,現(xiàn)在的ss無法在IDLE中正常顯示。而且我也沒有辦法把ss轉(zhuǎn)換成正常的編碼!比如采用下面的方法:

這有可能是因?yàn)镮DLE本地化做得不夠好,對(duì)中文的支持有問題。建議在IDLE的SHELL中,不要使用u“中文”這種方式,因?yàn)檫@樣得到的并不是你想要的東西。
這同時(shí)說明IDLE的Shell支持兩種格式的中文字符串:GBK編碼的“str”對(duì)象,和UNICODE編碼的unicode對(duì)象。
1.3 在IDLE上運(yùn)行代碼在IDLE的SHELL上運(yùn)行文件,得到的又是不同的結(jié)果。文件的內(nèi)容是:

直接運(yùn)行的結(jié)果是:

毫無瑕疵,相當(dāng)令人滿意。我沒有試過其它編碼的文件是否能正常運(yùn)行,但想來應(yīng)該是不錯(cuò)的。
同樣的代碼在windows的控制臺(tái)試演過,也沒有任何問題。
1.4 Windows Eclipse在Eclipse中處理中文更加困難,因?yàn)樵贓clipse中,編寫代碼和運(yùn)行代碼屬于不同的窗口,而且他們可以有不同的默認(rèn)編碼。對(duì)于如下代碼:
#!/usr/bin/python# -*- coding: utf-8 -*- s = '哈哈'ss = u’哈哈’ print repr(s)print repr(ss) print s.decode(’utf-8’).encode(’gbk’)print ss.encode(’gbk’) print s.decode(’utf-8’)print ss
前四個(gè)print運(yùn)行正常,最后兩個(gè)print都會(huì)拋出異常:’/xe5/x93/x88/xe5/x93/x88’u’/u54c8/u54c8’哈哈哈哈Traceback (most recent call last): File 'E:/Workspace/Eclipse/TestPython/Test/test_encoding_2.py', line 13, in <module> print s.decode(’utf-8’)UnicodeEncodeError: ’ascii’ codec can’t encode characters in position 0-1: ordinal not in range(128)
也就是說,GBK編碼的str對(duì)象可以正常打印,但是不能打印UNICODE編碼的unicode對(duì)象。在源文件上點(diǎn)擊“Run as”“Run”,然后在彈出對(duì)話框中選擇“Common”:
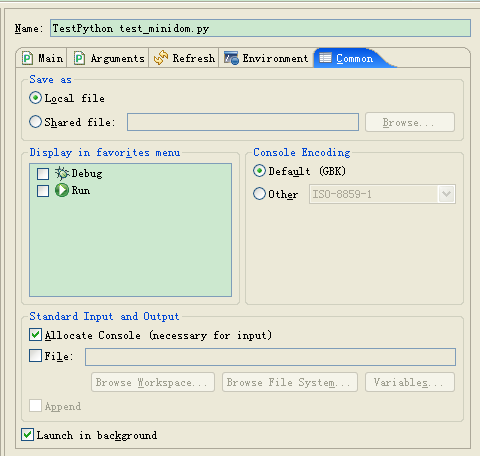
可以看出Eclipse控制臺(tái)的缺省編碼方式是GBK;所以不支持UNICODE也在情理之中。如果把文件中的coding修改成GBK,則可以直接打印GBK編碼的str對(duì)象,比如s。
如果把源文件的編碼設(shè)置成“UTF-8”,把控制臺(tái)的編碼也設(shè)置成“UTF-8”,按道理說打印的時(shí)候應(yīng)該沒有問題。但是實(shí)驗(yàn)表明,在打印UTF-8編碼的str對(duì)象時(shí),中文的最后一個(gè)字符會(huì)顯示成亂碼,無法正常閱讀。不過我已經(jīng)很滿足了,至少人家沒有拋異常不是:)
BTW: 使用的Eclipse版本是3.2.1。
1.5 從文件讀取中文在window下面用記事本編輯文件的時(shí)候,如果保存為UNICODE或UTF-8,分別會(huì)在文件的開頭加上兩個(gè)字節(jié) “/xFF/xFE” 和三個(gè)字節(jié)“/xEF/xBB/xBF”。在讀取的時(shí)候就可能會(huì)遇到問題,但是不同的環(huán)境對(duì)這幾個(gè)多于字符的處理也不一樣。
以windows下的控制臺(tái)為例,用記事本保存三個(gè)不同版本的“哈哈”。
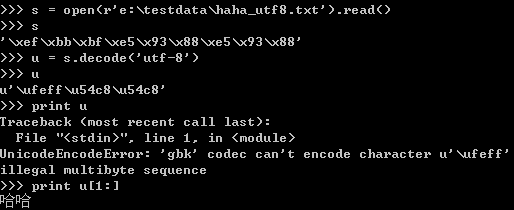
打開utf-8格式的文件并讀取utf-8字符串后,解碼變成unicode對(duì)象。但是會(huì)把附加的三個(gè)字符同樣進(jìn)行轉(zhuǎn)換,變成一個(gè)unicode字符,字符的數(shù)據(jù)值為“/xFF/xFE”。這個(gè)字符不能被打印。編碼的時(shí)候需要跳過這個(gè)字符。
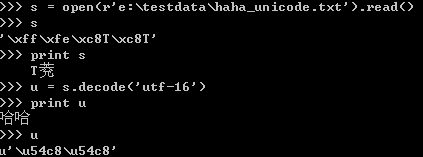
打開unicode格式的文件后,得到的字符串正確。這時(shí)候適用utf-16解碼,能得到正確的unicdoe對(duì)象,可以直接使用。多余的那個(gè)填充字符在進(jìn)行轉(zhuǎn)換時(shí)會(huì)被過濾掉。

打開ansi格式的文件后,沒有填充字符,可以直接使用。結(jié)論:讀寫使用python生成的文件沒有任何問題,但是在處理由notepad生成的文本文件時(shí),如果該文件可能是非ansi編碼,需要考慮如何處理填充字符。
1.6 在數(shù)據(jù)庫中使用中文剛剛接觸Python,我用的數(shù)據(jù)庫是mysql。在執(zhí)行插入、查找等操作時(shí),如果運(yùn)行環(huán)境使用的字符編碼和mysql不一致,就可能導(dǎo)致運(yùn)行時(shí)的錯(cuò)誤。當(dāng)然,和上面看到的情況一樣,運(yùn)行環(huán)境并不是關(guān)鍵因素,關(guān)鍵是查詢語句的編碼方式。如果在每次執(zhí)行查詢操作時(shí)都把查詢字符串做一次編碼轉(zhuǎn)換,轉(zhuǎn)變成mysql的默認(rèn)字符編碼,一樣不會(huì)遇到問題。但是這樣寫代碼也太痛苦了吧。
使用如下代碼連接數(shù)據(jù)庫:
self.conn = MySQLdb.connect(use_unicode = 1, charset=’utf8’, **server)
我不能理解的是既然數(shù)據(jù)庫用的默認(rèn)編碼是UTF-8,我連接的時(shí)候也用的是UTF-8,為什么查詢得到的文本內(nèi)容卻是UNICODE編碼(unicode對(duì)象)?這是MySQLdb庫的設(shè)置么?
1.7 在XML中使用中文使用xml.dom.minidom和MySQLdb類似,對(duì)生成的dom對(duì)象調(diào)用toxml方法得到的是unicode對(duì)象。如果希望輸出utf-8文本,有兩種方法:
1.使用系統(tǒng)函數(shù)在輸出xml文檔的時(shí)候進(jìn)行編碼,這是我覺得最好的方法。
xmldoc.toxml(encoding=’utf-8’)xmldoc.writexml(outfile, encoding = ‘utf-8’)
2.自己編碼生成
在使用toxml之后可以調(diào)用encode方法對(duì)文檔進(jìn)行編碼。但這種方法無法得到合適的xml declaration(xml文檔第一行中的encoding部分)。不要嘗試通過xmldoc.createProcessingInstruction來創(chuàng)建一個(gè)processing instraction:
<?xml version=’1.0’ encoding=’utf-8’?>
xml declaration雖然看起來像是,但是事實(shí)上并不是一個(gè)processing instraction。可以通下面的方法得到一個(gè)滿意的xml文件:
print >> outfile, “<?xml version=’1.0’ encoding=’utf-8’?>”print >> outfile, xmldoc.toxml().encode(‘utf-8’)[22:]
其中第二行需要過濾掉在調(diào)用xmldoc.toxml時(shí)生成的“<?xml version=’1.0’ ?>”,它的長度是22。
相面是兩種方法的用法比較:

另外,在IDLE的shell中,不要用 u’中文’ 對(duì)屬性進(jìn)行賦值。上面討論過,這樣得到的unicode字符串不正確。
到此這篇關(guān)于python中文編碼問題的文章就介紹到這了,更多相關(guān)中文編碼內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Python實(shí)現(xiàn)學(xué)生管理系統(tǒng)的代碼(JSON模塊)2. Python基礎(chǔ)之畫圖神器matplotlib3. JavaScript實(shí)現(xiàn)多球運(yùn)動(dòng)效果4. JAMon(Java Application Monitor)備忘記5. Python OpenCV去除字母后面的雜線操作6. Spring security 自定義過濾器實(shí)現(xiàn)Json參數(shù)傳遞并兼容表單參數(shù)(實(shí)例代碼)7. Java類加載機(jī)制實(shí)現(xiàn)步驟解析8. 增大python字體的方法步驟9. Python TestSuite生成測(cè)試報(bào)告過程解析10. Python os庫常用操作代碼匯總

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備